
This one is trying to demo the basic operation of DataFrame.
import pandas
%matplotlib inline
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
read_csv,plot and math
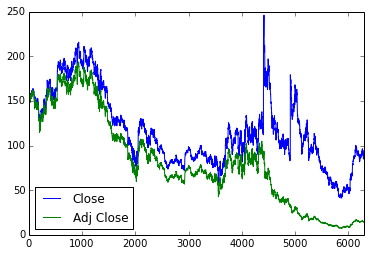
def get_max_close(symbol):
"""
return the max close value of the specified stock
"""
df = pd.read_csv("stock/data/{}.csv".format(symbol))
#print df.head(5)
df[['Close','Adj Close']].plot()
plt.show()
return df['Close'].max()
def test_run():
for symbol in ['AAPL','IBM']:
print symbol,get_max_close(symbol)
test_run()
AAPL,702.100021
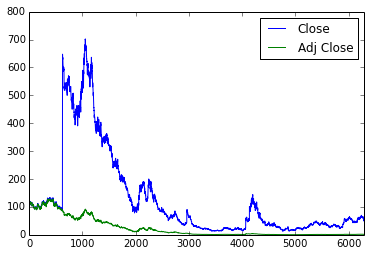
IBM,246.0
pd.join
dt = pd.date_range('2010-01-22','2010-01-26')
#print dt, dt[0]
df1=pd.DataFrame(index=dt)
dfspy=pd.read_csv('stock/data/SPY.csv',index_col='Date',parse_dates=True,usecols=['Date','Adj Close'],na_values=['nan'])
#print dfspy.head()
df2=df1.join(dfspy)
#print df1
df2=df2.dropna()
print df2
then, the output is:
Adj Close
2010-01-22 95.201720
2010-01-25 95.689887
2010-01-26 95.288892
make good use of parameters of JOIN in a sentence of Code as the following:
df2=df1.join(dfspy,how='inner')
print df2
then the output is:
Adj Close
2010-01-26 95.288892
2010-01-25 95.689887
2010-01-22 95.201720
note: there are 4 options for the parameter how
- inner
- outer
- left
- right
rename the column name in DataFrame
print df2.head()
df2 = df2.rename(columns={'Adj Close':'SPY'})
print df2
then the output is:
Adj Close
2010-01-26 95.288892
2010-01-25 95.689887
2010-01-22 95.201720
SPY
2010-01-26 95.288892
2010-01-25 95.689887
2010-01-22 95.201720
Slice
import os
def symbol_to_path(symbol, base_dir="stock/data"):
"""Return CSV file path given ticker symbol."""
return os.path.join(base_dir, "{}.csv".format(str(symbol)))
def get_data(symbols, dates):
"""Read stock data (adjusted close) for given symbols from CSV files."""
df = pd.DataFrame(index=dates)
if 'SPY' not in symbols: # add SPY for reference, if absent
symbols.insert(0, 'SPY')
for symbol in symbols:
# TODO: Read and join data for each symbol
df1 = pd.read_csv(symbol_to_path(symbol),index_col='Date', usecols=['Date','Adj Close'],parse_dates=True,na_values=['nan'])
df1=df1.rename(columns={'Adj Close':symbol})
df = df.join(df1)
if symbol=='SPY':
df=df.dropna()
return df
def test_run():
# Define a date range
dates = pd.date_range('2010-01-01', '2010-10-31')
# Choose stock symbols to read
symbols = ['GOOG', 'IBM', 'AAPL']
# Get stock data
df = get_data(symbols, dates)
fig = df.plot(title='stock graph')
fig.set_xlabel('month')
fig.set_ylabel('price')
plt.show()
df = df.ix['2010-01-01':'2010-01-08']
print df.head(20)#.ix['2010-01-20':'2010-02-28']
df = df.ix[:,['SPY','GOOG']] # or df = df[['SPY','GOOG']]
print df
test_run()
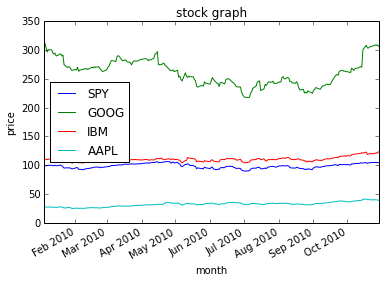
SPY GOOG IBM AAPL
2010-01-04 98.793254 313.062468 112.285875 27.847252
2010-01-05 99.054769 311.683844 110.929466 27.895396
2010-01-06 99.124509 303.826685 110.208865 27.451683
2010-01-07 99.542943 296.753749 109.827375 27.400936
2010-01-08 99.874198 300.709808 110.929466 27.583106
SPY GOOG
2010-01-04 98.793254 313.062468
2010-01-05 99.054769 311.683844
2010-01-06 99.124509 303.826685
2010-01-07 99.542943 296.753749
2010-01-08 99.874198 300.709808




近期评论