
Sponsored Post.By Brandon Dey, ODSC
With ODSC West 2018 in the history logs, it didn’t disappoint. Conferences can be overblown, and usually in proportion to the number of buzzwords marketed in its runup. ODSC West wasn’t; I went home with a number of practical tricks I will apply to the machine learning problems that await me at my day job.
For starters, now I can succinctly disambiguate the terms “Data Science” and “Machine Learning” to my laymen colleagues, thanks to a talk by Amir Najmi, Principal Data Scientist at Google. Najmi said
Data Science “frames decisions to be made under uncertainty,”while Machine Learning is but one of many data science tools that is “…not concerned with [the] provenance or truth of [a] model.”
Najmi demonstrated he hasn’t drunk the well-documented conflation Kool Aid.
This was a sobering perspective of our field, given how current media is tripping over buzzwords, and who better to hear it from than one of the co-editors of Google’s Unofficial Data Science blog.
(Active) Learnings
Easily one of my favorite presentations was from Alex Spangher, a Data Scientist at the New York Times. He explained how the NYT Data Science team helped the iconic publication lure advertisers to the platform by equipping them with the power to pair their adverts with articles most likely to evoke the emotion — hope, fear, anger, love, etc. — most relevant to their ad. (That tool is used nowhere near the newsroom to preserve journalistic integrity.) I haven’t had many good applications of NLP (natural language processing) at work — my exposure to it has been limited to sentiment analysis — so when he shared how they built emotion-specific deep learning models, I was stoked.
The real value of his talk for me, however, was a description of active learning, a resampling method he and his team used to make the most out of the dearth of articles labeled with the emotions they evoke. As you can imagine, reading hundreds of thousands of New York Times articles would be financially and temporally prohibitive, so sidestepping this is a no-brainer. They used mechanical turk to read and rate certain articles for their training set, but they didn’t rate just any article. Only the articles that would be the most helpful to their models were selected, where most helpful was defined as harder to predict. Spangher and his colleagues used active learning to select the most helpful articles, and continued the process until adding more articles stopped improving accuracy. This led to a meaningful boost in predictive power, one that was validated via randomized trial. Very cool. I’ll be putting this to use soon.
Interactive coefficient plots
Another helpful talk was from R for Everyone author Jared Lander, Principal Data Scientist at Lander Analytics, and a Columbia professor. He regaled an audience of data science enthusiasts for nearly eight hours on some of the most useful machine learning techniques in R — like elastic net and random forest. By far the coolest thing I learned was how to visualize an interactive coefficient pathway plot (shown below) for penalized regression using coefplot::coefpath() (try it!).
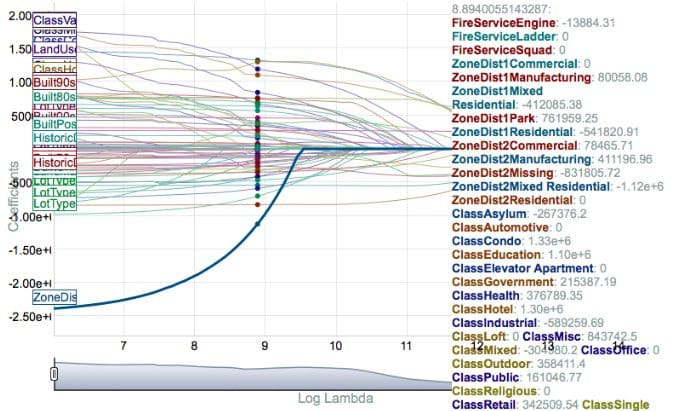
I was hard-pressed to find an attendee who was dissatisfied — and I actually asked — in part because of the sheer magnitude of content. 320 hours of content from over 200 speakers was shoehorned into four, eight-hour days — just 32 hours — meaning, yea, you might miss the talk on that one thing you haven’t had time to investigate yet.
But organizers minimized this by scheduling R talks in tandem with the Python talks so you were usually only sacrificing a talk in another language. My point is: It wasn’t just the technical content that made ODSC worth the trip, it was organized to maximize my learning, too.
Even so, there were a few talks I would have like to see, time permitting:
- “Potentials and Challenges of DS in Quantitative Investment” by Kazuhiro Simbo
- “Intermediate R Markdown in Shiny” by Jared Lander
- “The Platform and Process of Agile Data Science” by Sarah Aerni
- “Tuning the Un-tunable: Lessons for tuning expensive deep learning functions” by Scott Clark
- “Continuous Experiment Framework at Uber” by Jeremy Gu
- “Time-series Forecasting: Predicting a Model’s Performance in an Unknown Future” by Noah Dolev
All is well, since ODSC East is coming up at the end of April. But in the meantime, watch the West videos when they are available!
Note: Fortunately, many of these talks were captured on video, so one can watch them after the fact! Attendees get first access, but most talks eventually make it up to YouTube.




近期评论