
** Fri 12 October 2018
This blog posts discusses the design and performance implications of using
bitmaps to mark null values instead of sentinel values (or special values like
NaN).
Depending on who you talk to, one controversial aspect of the Apache Arrow
columnar format is the fact that it uses a validity bitmap to mark value as
null or not null. Here’s the basic idea:
The number of nulls is a property of an array, generally computed once then
stored
- If an array has any null values at all, then a bitmap must be allocated
If the value at bit i is 0, then the value is null, otherwise it is not
null
There’s some nice benefits of the bitmap approach:
If an array has no nulls, then the bitmap can be ignored or simply not
allocated at all
Nulls can be propagated in algorithms by using word-wise AND or OR
operations, processing 32 or 64 values at a time
Still, for systems like R which use special values to mark nulls, bitmaps can
be controversial. The argument sometimes centers on the performance
implications of having to check bits rather than comparing a value with
INT32_MIN or checking if it is NaN. It is also noted that NaN values are
propagated automatically by the CPU in arithmetic operations, so propagating
nulls in the bitmap case will be necessarily slower.
From the perspective of databases and data warehousing, reserving certain
values to mark a null (or NA) is widely considered unacceptable. NaN is valid
data, as is INT32_MIN and other common values used as sentinels.
Most SQL systems store the null-ness of value using an extra bit or byte. File
formats like Apache Avro and Parquet have a separate null/not-null encoding.
To show that the performance argument against bitmaps is not persuasive, I
wrote some in-memory performance benchmarks (I would like to do some
experiments with large memory-mapped datasets). To keep things simple, let’s
consider the sum operation which must aggregate all of the non-null values in
an array. We also will track the non-null count.
We are interested in a few typical cases:
- Data with no nulls
- Data with a small percentage of nulls, say 10%
- Data with a high percentage of nulls, say 50%
To keep track of the results of a sum, I use a simple struct, templated on the
type of the values:
The naive sum looks like this
Let’s consider double precision floating point values, where NaN is a common
sentinel value. So a sum function for double is:
If we represent nulls with bits, we could write the sum naively like so:
It’s possible to go much faster using bitmaps with a few optimization
techniques:
Eliminate the “if” statements by using floating point operations to
conditionally add the non-null values
- “Unroll” part of the for loop to sum 8 values at a time
Skip null checking for groups of 8 values with no nulls. This is made faster
still by generating a pre-populated table of bit popcounts for uint8_t
values.
Here’s the meat of this new vectorized sum algorithm:
To give a fair comparison with a sum without nulls, I also wrote similar
versions of this that sums 8 values at a time in the non-nullable case and
NaN sentinel value case. I also added the same benchmark with int64 values
using INT64_MIN as the sentinel value in case integer operations perform
differently from floating point operations.
Complete benchmarking code is here. Here are the performance results
for the 3 cases there there are 0%, 10%, and 50% nulls, respectively. The size
of the array being summed is 10 million values. The machine is my Xeon E3-1505M
Linux laptop.
It’s definitely possible that I’m doing something suboptimal in my
implementations. I would love to hear from algorithms experts!
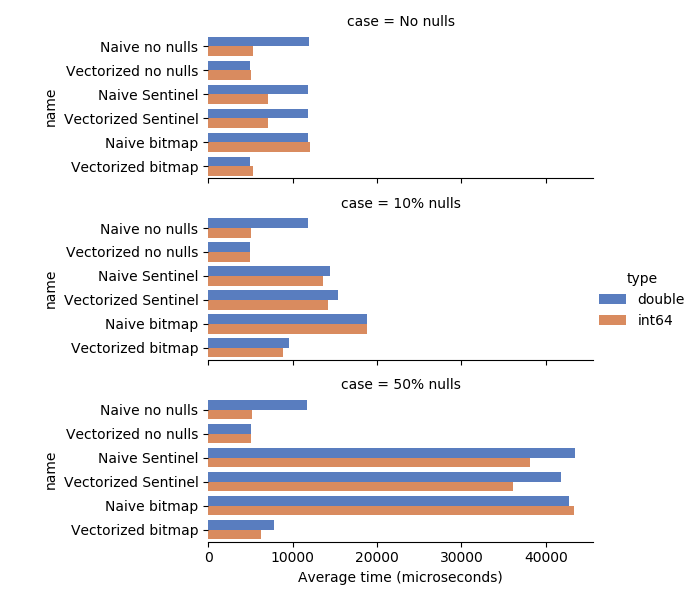
Some observations on these benchmark results:
The “no nulls” sum functions, both vectorized and not, perform the same for
all 3 cases, since it does no null checking at all
When there are no nulls, there is no performance penality with the optimized
bitmap sum
When there are 10% nulls, the bitmap sum is about 30% faster than the
sentinel-based sum. The performance gap widens when the percentage of nulls
is higher.
The vectorized bitmap sum is faster when there are 50% nulls than when there
are 10% nulls. I am not sure why this is; I would speculate that because on
average many of the terms in the sum are 0 that the processor is able to
avoid some floating point operations. It might be possible to further
optimize by reducing the number of possible FP operations using a “binary
tree” sum.
- Vectorization / batching brings little benefit to the sentinel-based algorithm
Using a bit- or byte-based masked null representation is a requirement for a
common memory format to be accepted by database systems as well as data science
libraries, so using sentinel values at all is not really an option in a project
like Apache Arrow. But, in many cases, using bitmaps allows faster algorithms
to be developed that are not possible with the sentinel value-based null
representation used in pandas and R.
I’m not a perfect programmer, so I’ll be interested to see what other kinds of
optimizations others can cook up. Take a look at the benchmark code!




近期评论