
Hash Table이란, 검색하고자 하는 key 값을 입력받아서 해시함수를 돌려서 반환받은 해시코드를 배열의 인덱스로 환산해서 데이터에 접근하는 방식의 자료구조이다.
Hash Table 작동원리
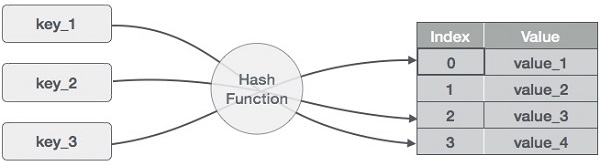
출처: Hash Table
- 검색하고자 하는 Key 값을 해시함수를 돌리면, 해시코드를 반환받는다.(해시코드는 정수이다)
- 반환된 해시코드를 배열의 개수로 나머지(%) 연산을 해서 인덱스 번호로 바꾼다. 예를 들어, 어떤 Key 값의 해시코드가 445이고 배열의 크기가 3이면, 445 % 3 = 1이 되어, 인덱스 번호는 1이 된다.
- 이 인덱스 번호로 배열에 데이터를 저장한다. 예를 들어, 인덱스 번호가 1이라면, 배열에서 배열방 1번에 저장한다.
- 즉, 해시코드 자체가 배열방의 인덱스로 사용되어 검색이 필요없고, 해시코드로 바로 배열의 데이터에 접근이 가능하다.
- 각 배열방에 저장되어 있는 데이터들은 연결 리스트로 되어 있어, 배열방에 새로운 데이터가 추가될 때마다, 연결 리스트에 추가가 된다.
- 어떤 Key 값에 대한 검색 요청이 들어와 인덱스로 환산한 뒤, 어떤 배열방에서 그 Key 값을 찾기 위해서는, 그 배열방에 연결 리스트를 순회화면서 그 Key 값을 찾는다.
Hash Table 특징
-
장점: 해시코드 자체가 배열방의 인덱스로 사용되어 다른 검색이 필요없이 해시코드로 바로 배열의 데이터에 접근이 가능하기 때문에, 시간복잡도가 O(1)이다.
-
단점: 1개의 배열방에 여러 데이터가 겹쳐서 저장되는 경우를 Collision(충돌)이라고 하는데, 이 경우 시간복잡도는 O(n)이다. 이는, 배열방에서 그 Key 값을 찾기 위해, 그 배열방에 연결 리스트를 순회화면서 그 Key 값을 찾아야 하기 때문이다. 이런 문제가 생기는 경우는 크게 2가지이다.
-
서로 다른 Key 값이지만, 동일한 해시코드로 반환받는 경우
- Key 값은 문자열이고 그 가짓수가 무한한대 반해서 해시코드는 정수개 밖에 제공을 못하기 때문에, 알고리즘이 아무리 좋아도 어떤 Key들은 중복되는 해시코드를 가질 수 밖에 없다.
-
서로 다른 해시코드이지만, 동일한 인덱스로 바뀌는 경우
- 배열방은 한정되어 있기 때문에, 서로 다른 해시코드이더라도, 환산할 때 동일한 인덱스를 얻게 되는 경우가 있을 수 있기 때문에, 같은 배열방에 배정받는 경우도 있다.
-
이런 Collision을 최소화하기 위해서는 좋은 해시 알고리즘을 만드는 것이 중요하다. 즉, 배열방을 나눌 때, 규칙을 잘 만들어야 한다.




近期评论