
Weka provides different tools for different purpose in the Weka workbench. Weka Experimenter offers a systematic way of assessing multiple models on multiple datasets effectively in one place.
Assess single model
Most machine learning models come with some randomness that can be specified by random seed. To make sure the result accuracy is not by chance, Experimenter offers the facility to run model with different seed of specified number of iterations. The mean and standard deviation of accuracy of multiple run delivers more reliable assessment of model performance.
As illustrated here, I test J48 performance with 10 fold cross validation and 10 iterations. That’s totally 100 results. In the test output panel, the averaged prediction accuracy and its standard deviation are calculated. That is more reliable result than just doing 10 fold cross valiation in explorer as the 10 iterations tend to use different random seed.
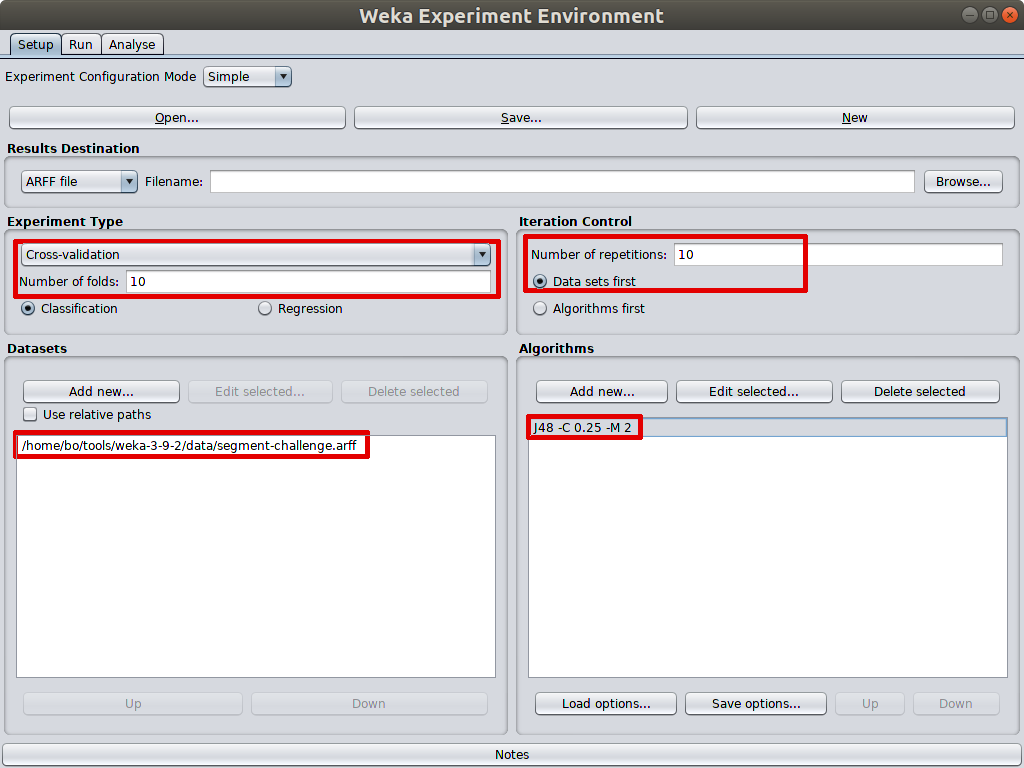
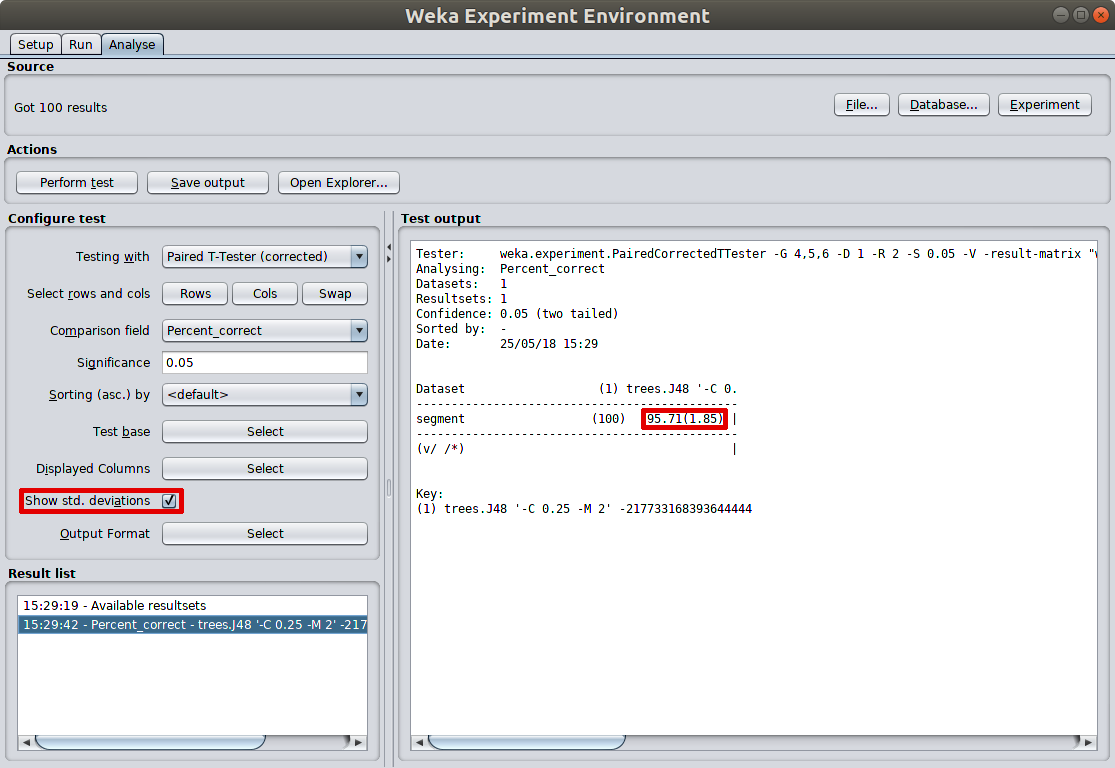
Experimenter also offers saving detailed running detail of each iteration into a file for further analysis, which is an awesome facility to have when something goes wrong with the model.
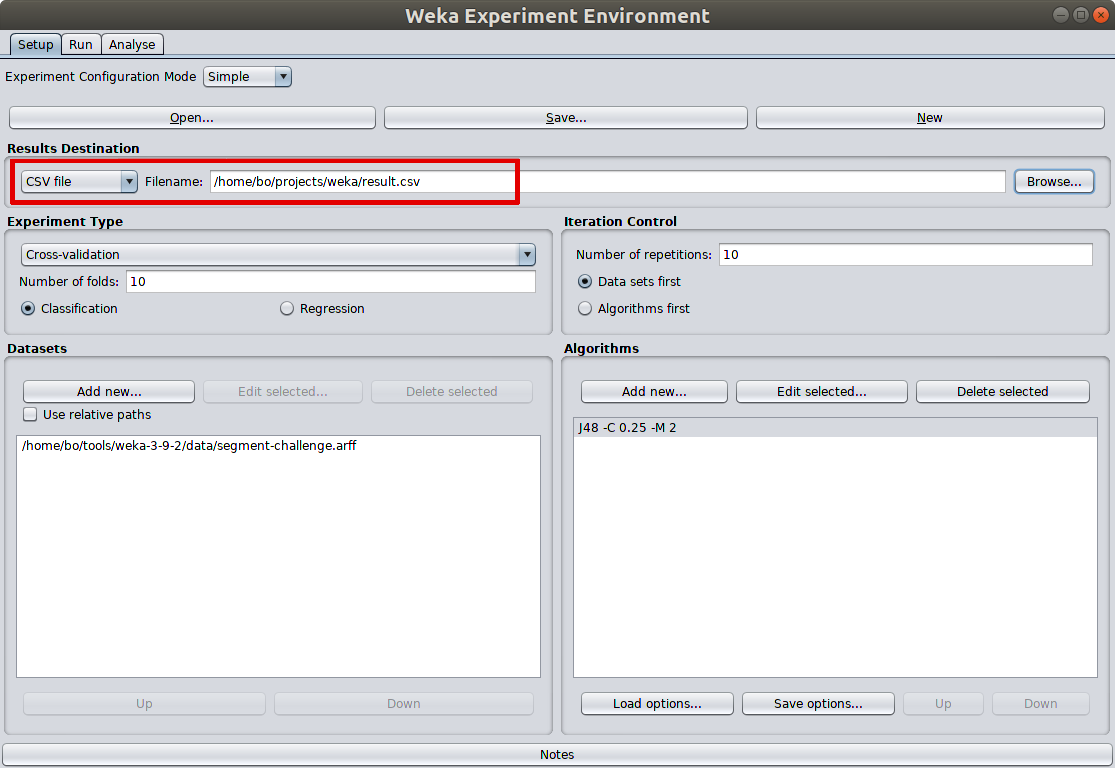
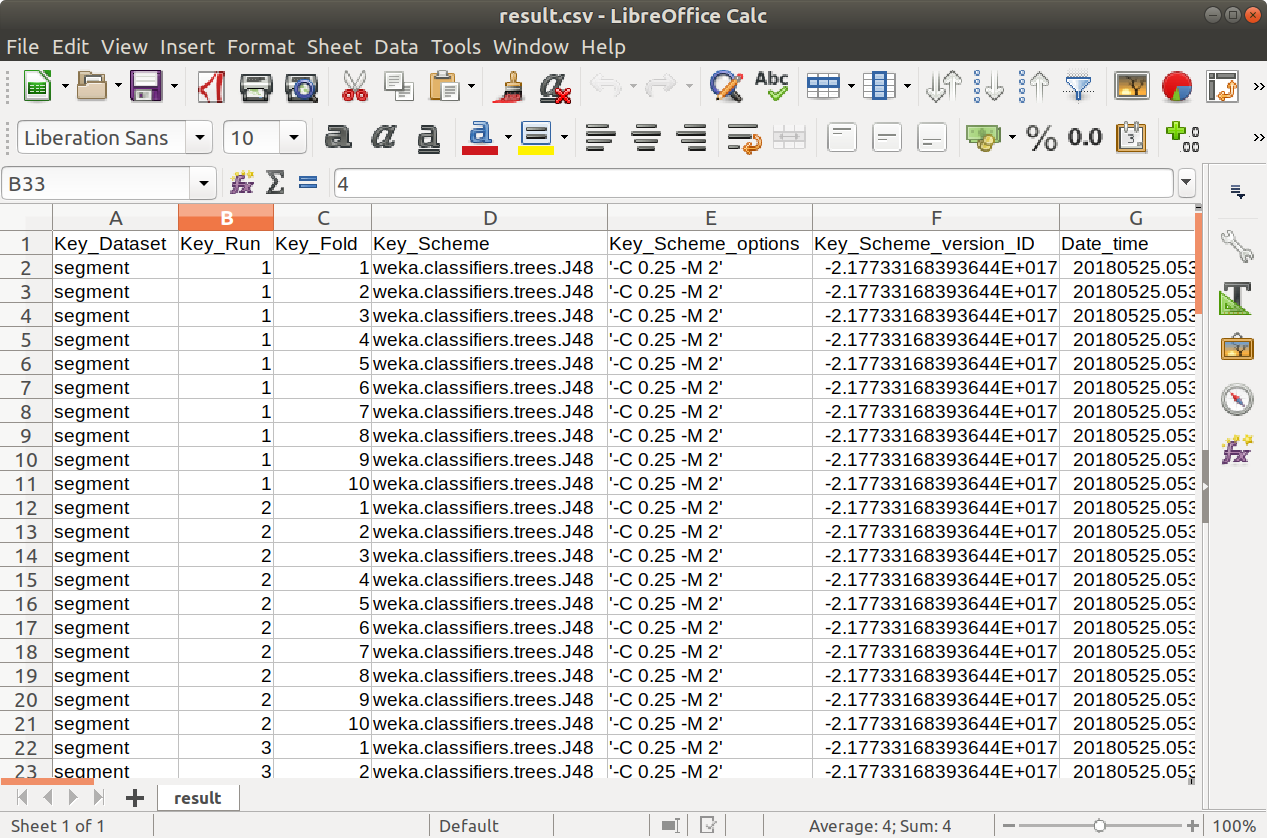
Weka Experimenter stores 70 columns of model attributes into result file, which preserves full details for further analysis.
Compare different models
What is more powerful is that Experimenter can perform test on multiple datasets with multiple machine learning models. As illustrated below, 4 machine learning models are selected to test on 2 datasets.
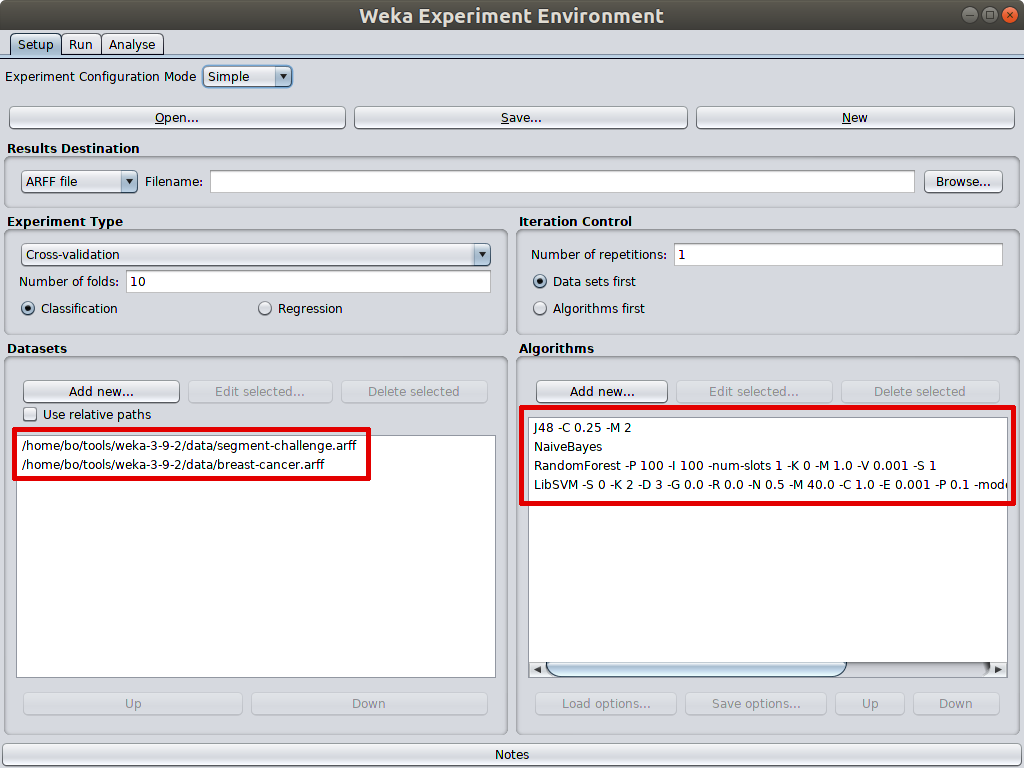
In the analysis tab, comparision field can be set to different measurement, such as F_measure, Kappa_statistic, but the most common is percent_correct, which is accuracy as it is selected in the example. Statistical significance is set to 0.05 by default which is suitable for most cases.
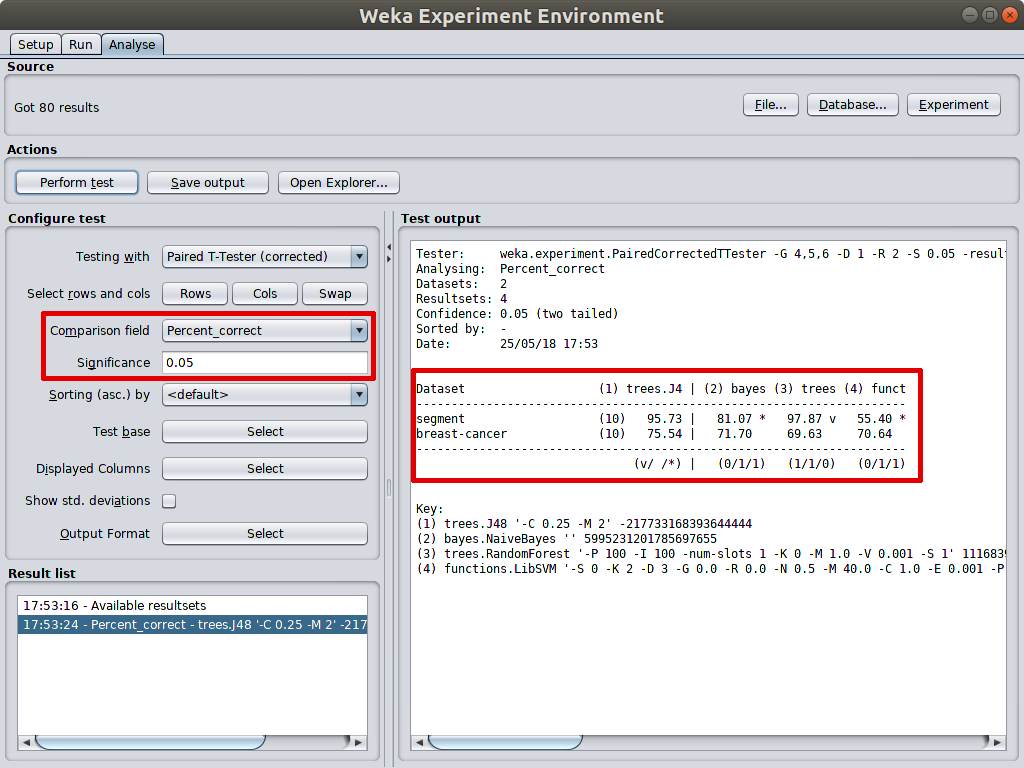
In the test output panel, J48 is selected as test base for comparison. the accuarcy marked star meaning significantly lower than test base algorithm’s accuarcy. As in the example, the accuracies of naive bayes and SVM are significantly poorer than J48’s on segment_challenge dataset. On the contrary, the accuracy of Random forest is significantly better than J48’s. That is why accuracy of random forest is marked v on the right. When there are no signs marked, the compared measurement is insignificantly poorer or better than that of test base model. As in the example, all 3 compared algorithms are insignicantly better or worse than J48 on breast-cancer dataset.




近期评论