
Baseline accuracy
What is baseline accuracy in data mining? In Weka, it provides a simple algorithm called ZeroR. It simply finds the most popular class in the training dataset and guesses that all the time.
For example, in the famous diabetes dataset, there are 500 nagative class instances and 268 positive class instances as shown in the Preprocess panel.
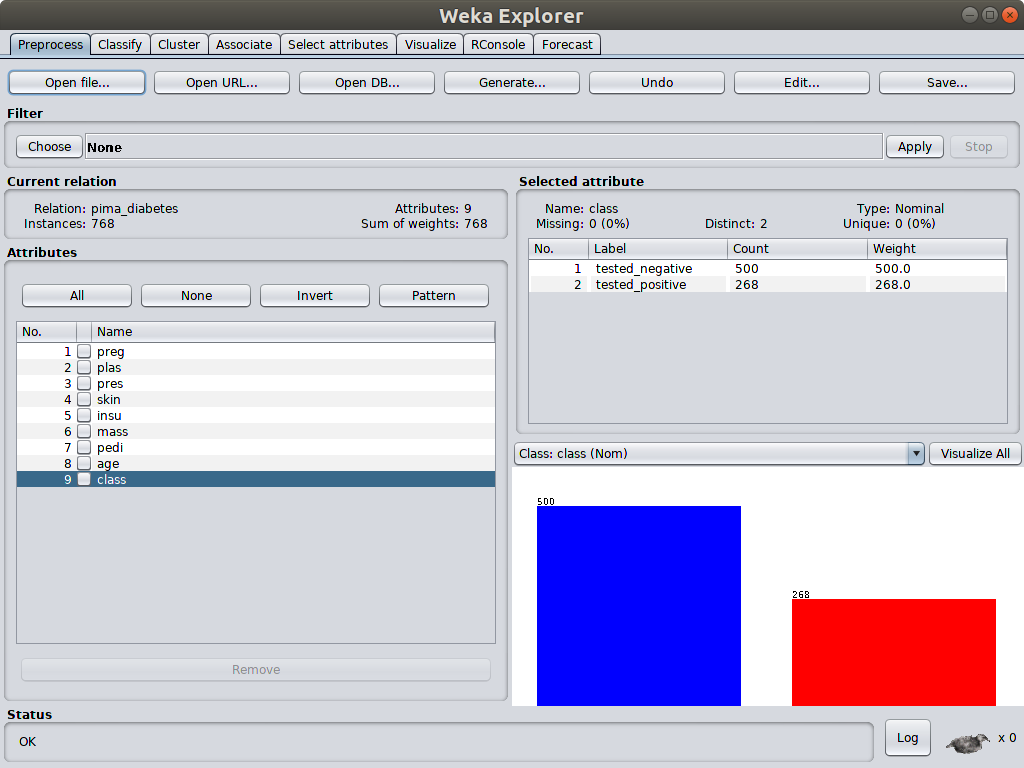
ZeroR algorithm always predicts the majority class in the training dataset, which is positive class here. Therefore, the accuracy when doing this in the training set is 500/(500 + 268) = 0.65, which is exactly the same accuracy calculated in classify panel when applying ZeroR.
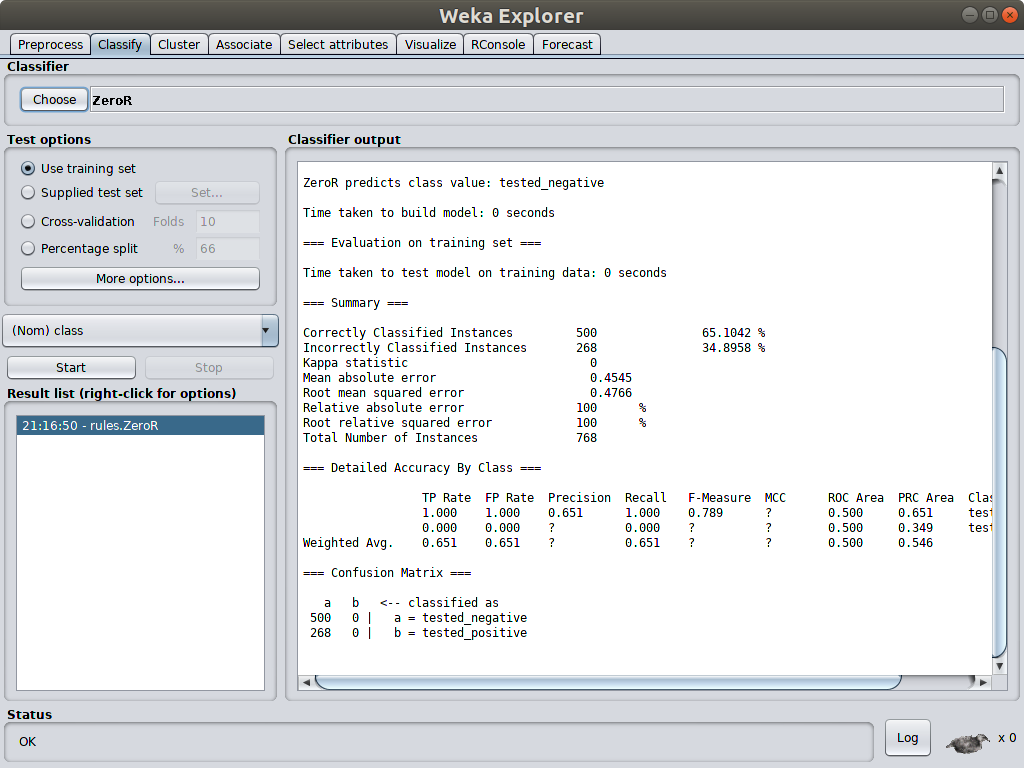
Any data mining algorithm to be useful should have accuracy higher than the gambling style algorithm. That is why ZeroR is the baseline accuracy and it should always be the baseline to start with.
Simplicity first
In data mining, simple algorithms often work very well. Besides, simple algorithms are easy to understand and help data scientists to learn from data. That is why data scientists should always try simple algorithms before trying more complicated ones.
In Weka, there are some recommended simple classification algorithms to start with. For example, OneR is an algorithm that builds one branch decision tree from training data, and let one attribute does all the prediciton work. Another simple algorithm is naive bayes algorithm, which assumes all the attributes contribute equally and independently.
Of course, J48, which is the decision tree algorithm in Weka, is the most frequently applied algorithm in Weka environment. It often offers excellent prediction accuracy and interpretibility.
Data mining is an experimental science, the result depends on the application domain and it is always recommended to try simple methods first.




近期评论