defHierarchicalCluster(data, k): n, p = data.shape clustersSet = [] ## input all individual points as clusters for i in range(n): clustersSet.append([i]) ## initial a heap to sort distance between pair of clusters queue = PriorityQueue() ## compute a distance map distmap = np.zeros((n, n)) for i in range(n-1): for j in range(i+1, n): dist = np.linalg.norm(data[i]- data[j]) distmap[i][j] = dist distmap[j][i] = dist ## push all pair in the lowest level into a heap for i in range(n-1): for j in range(i+1, n): dist = distmap[i][j] pair = Pair([i], [j], dist) queue.push(pair, dist) ## deletedCluster = [] while(len(clustersSet) > k): pair = queue.pop() if pair.cluster1 in deletedCluster or pair.cluster2 in deletedCluster: continue new_cluster = pair.cluster1 + pair.cluster2 ## merge two cluster clustersSet.remove(pair.cluster1) clustersSet.remove(pair.cluster2) deletedCluster.append(pair.cluster1) deletedCluster.append(pair.cluster2) for cluster_t in clustersSet: dist_t = computeMinDist(new_cluster, cluster_t, distmap) pair_t = Pair(new_cluster, cluster_t, dist_t) queue.push(pair_t, dist_t) clustersSet.append(new_cluster) return clustersSet
The implementation of K means algorithms with Kernel is shown as the code below. For a valid Kernel, it is an inner product of the data in some Reproducing Kernel Hilbert Space.
The distance of $phi(x_1)$ and $phi(x_2)$ can be defined as $||phi(x_1) - phi(x_2)||^2_2$ using the square of L2 distance.
The center of a cluster $pi_k$is as below, $|pi_k|$ is the number of points in this cluster, $c_k$ is the center of this cluster.
For a point $x_j$, its distance to a cluster center is
From the equations above, we know that we can use K means in a RKHS space without knowing how the data is mapped to that space. Only know the inner product $K(x_i, x_j)$ is enough to implement the Kernel K means algorithms.
defKernelKmeans(data, k, epoch, kernel): n, p = data.shape c_idx = np.random.choice(n, k, replace=False) clusters = {} epoch_count = 10000 GramMatrix = np.zeros((n, n)) ## initialization for i in range(n): for j in range(i, n): GramMatrix[i][j] = kernel(data[i], data[j]) GramMatrix[j][i] = GramMatrix[i][j] for i in range(k): clusters['cluster_'+str(i)] = [] clusters['cluster_'+str(i)].append(c_idx[i]) diff_sum = 1 while diff_sum > 0.000: epoch_count -= 1 ## use all points in a cluster to update new_cluster = [[] for i in range(k)] for i in range(n): distances = np.zeros(k) for j in range(k): ## we do not know the center in that high feature space term1 = GramMatrix[i][i] points = clusters['cluster_'+str(j)] size = len(points) term2 = 2* np.sum(GramMatrix[i][points]) / size term3 = np.sum(GramMatrix[points, :][:, points])/(size**2) distances[j] = term1 - term2 + term3 min_idx = np.argmin(distances) new_cluster[min_idx].append(i) diff_sum = 0 for j in range(k): old_cent = np.mean(data[clusters['cluster_'+str(j)]], axis=0) new_cent = np.mean(data[new_cluster[j]], axis=0) diff_sum += np.linalg.norm(old_cent - new_cent) clusters['cluster_'+str(j)] = new_cluster[j] del new_cluster return clusters

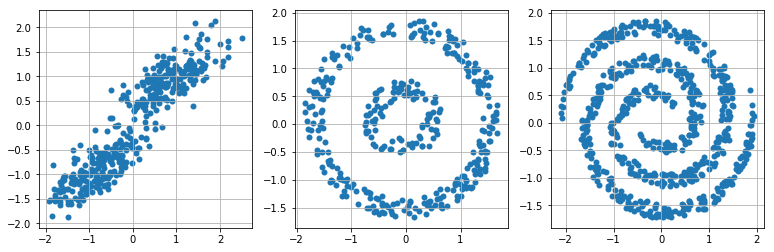
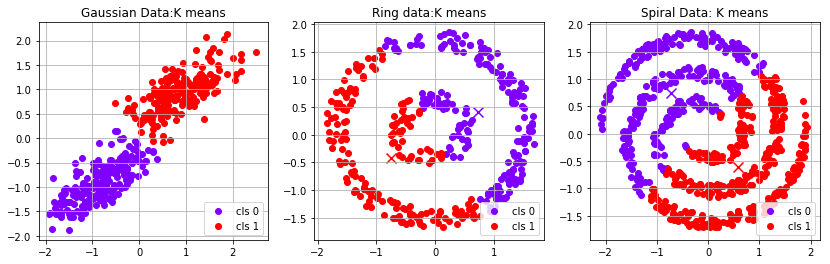
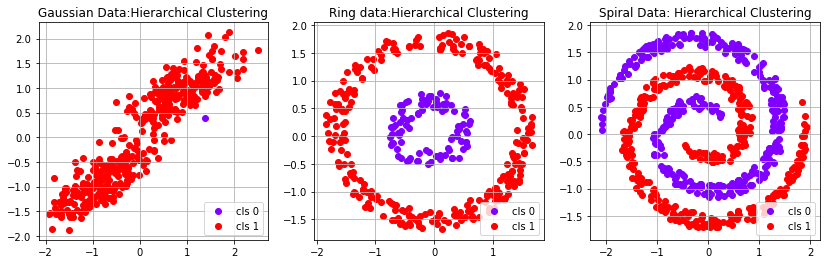
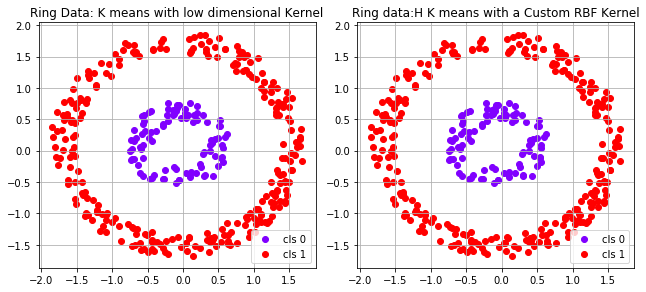




近期评论