
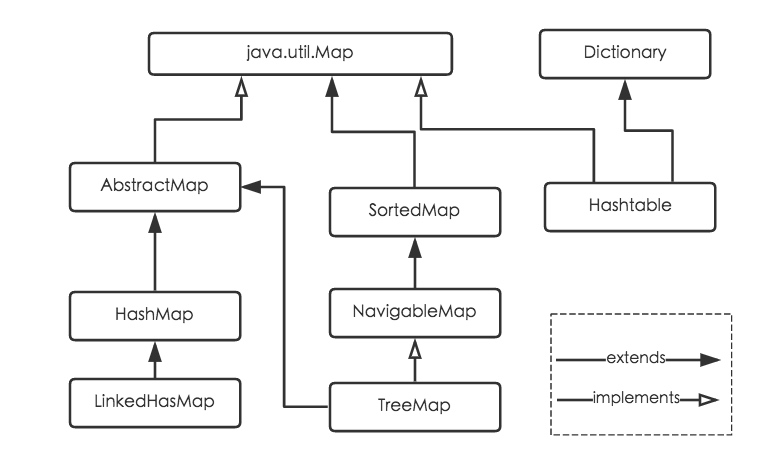
HashMap是一个关联数组、哈希表,其中数组被称为哈希桶,每个桶里放的是单链表或红黑树,每个节点就是哈希表中的元素。
特点是
- 线程不安全(线程安全可使用
ConcurrentHashMap)
- 遍历无序
- 允许单个null的key和多个null的值
JDK1.8后,新增了红黑树,当单个链表的元素达到8,就会转换成红黑树,提高查询和插入的效率,避免链表过长的问题
需要关注的问题
- hash表,涉及到
碰撞解决
- 数组,涉及到
扩容机制
Hash知识补充
Hash就是把任意长度的消息(预映射:pre-image)通过哈希算法压缩成固定长度的消息输出,输出的值就是Hash值。不同的输入可能有同样的输出,所以用Hash值得不到唯一值,同样的输出
称为碰撞需要进行碰撞处理:一般有:
拉链法(open hashing)、开放定址法(closed hashing)、再哈希法、建立公共溢出区
二、碰撞解决
从源码可知,HashMap中非常重要的一个字段, Node[] table,即Hash桶数组,Node的数组。
1
2
3
4
5
6
7
8
9
10
11
12
13
|
static class <K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {...}
public final K getKey() { ... }
public final V getValue() { ... }
public final String toString() { ... }
public final int hashCode() { ... }
public final V setValue(V newValue) { ... }
public final boolean equals(Object o) { ... }
}
|
Node是HashMap的一个内部类(JDK1.7对应类名Entry),实现了Map.Entry接口,本质是就是一个键值对。每一个节点存储的就是一个Node
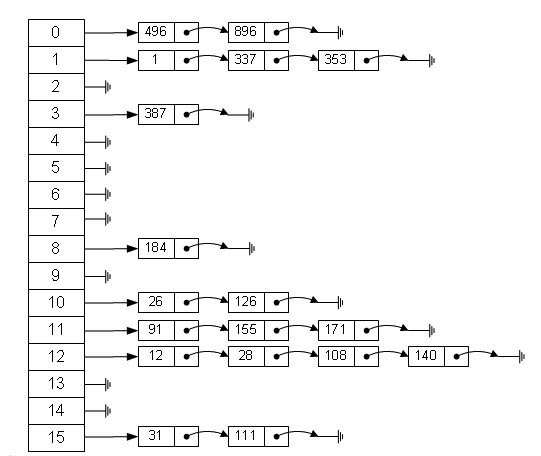
HashMap使用的是Hash表存储,并且使用拉链法解决碰撞。简单来说,就是数组加链表的结合.
当数据被Hash后,得到数组下标,把数据放在对应下标元素的链表。如果发生了碰撞,就会把数据插到对应链表的尾部(JDK1.7是插到头部,插到尾部避免了逆序,环形链表,后文会讲到)
三、扩容机制
理解扩容机制之前需要看一下几个重要的参数
1
2
3
4
5
6
7
8
9
10
11
12
13
|
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
static final float DEFAULT_LOAD_FACTOR = 0.75f;
int threshold;
final float loadFactor;
int modCount;
int size;
|
-
threshold是HashMap所能容纳的最大数据量,计算公式是threshold = length * loadFactor
当存储个数size大于threshold,容量扩大为原来的两倍
-
modCount用来记录HashMap内部结构发生变化的次数,主要用于迭代的快速失败.需要注意的是,put键值对的时候,某个key的value被覆盖不属于结构变化
-
loadFactor 负载因子默认值是0.75,这是对空间和时间成本的一种折中,一般情况下不需要修改,负载因子越大,对空间利用越充分,查询效率也越低,负载因子越小,哈希表的数据越稀疏,对空间浪费也越严重
-
DEFAULT_INITIAL_CAPACITY 初始容量为16,且为2的幂,采用这种非常规设计,主要是为了在取模和扩容时做优化,同时为了减少冲突,HashMap定位哈希桶索引位置时,也加入了高位参与运算的过程。
下面来分析一下resize的源码,鉴于红黑树比较复杂,这里先看JDK1.7
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
|
本质上就是从新创建一个大数组,并且把原来的数据转移过来,下面是转移的过程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
|
e的引用复制给了newTable[i],也就是说这里使用了单链表的头插法,而且需要重新计算每个元素的hash值,这两点与JDK1.8有区别,
下面要分析一下JDK1.8中做的优化,从JDK1.8的代码可以看出,数组的长度扩展为原来的2倍
所以,元素的位置要么是在原位置,要么是在原位置再移动2次幂的位置,下图就可以看的出来
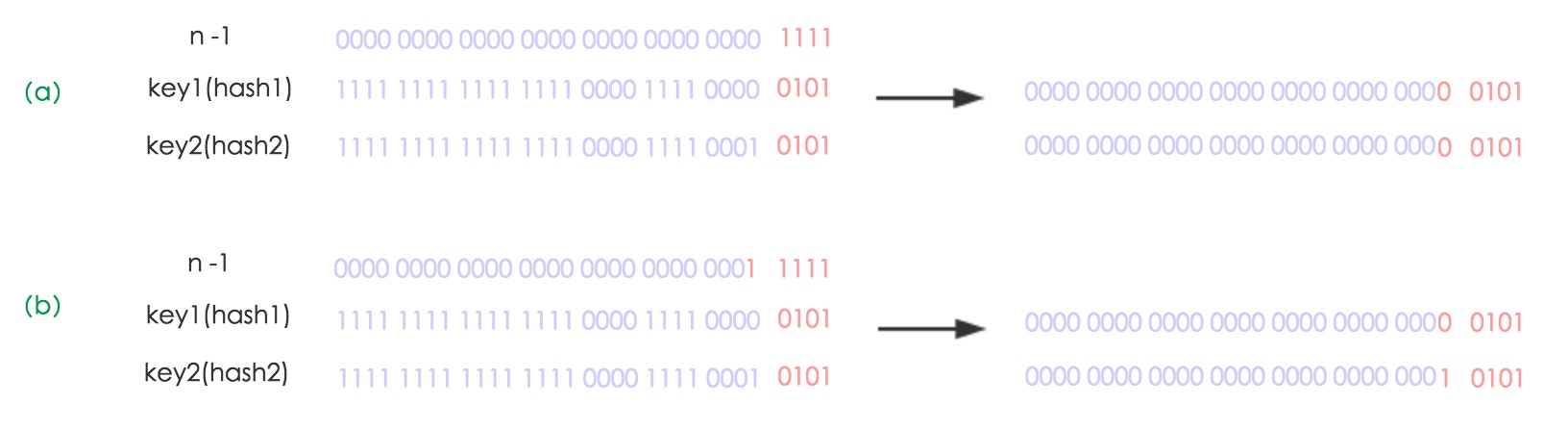
a,b分别是扩容前和扩容后,hash1无变化,hash2高位变成了1,所以index也就有了这样的变化
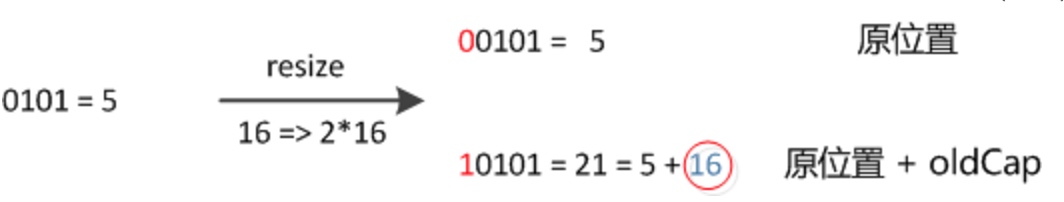
我们在扩充HashMap的时候,不需要像JDK1.7的实现那样重新计算hash,只需要看看原来的hash值新增的那个bit是1还是0就好了,是0的话索引没变,是1的话索引变成"原索引+oldCap"
1
|
newTab[e.hash & (newCap - 1)] = e
|
下图为16扩充为32的resize示意图
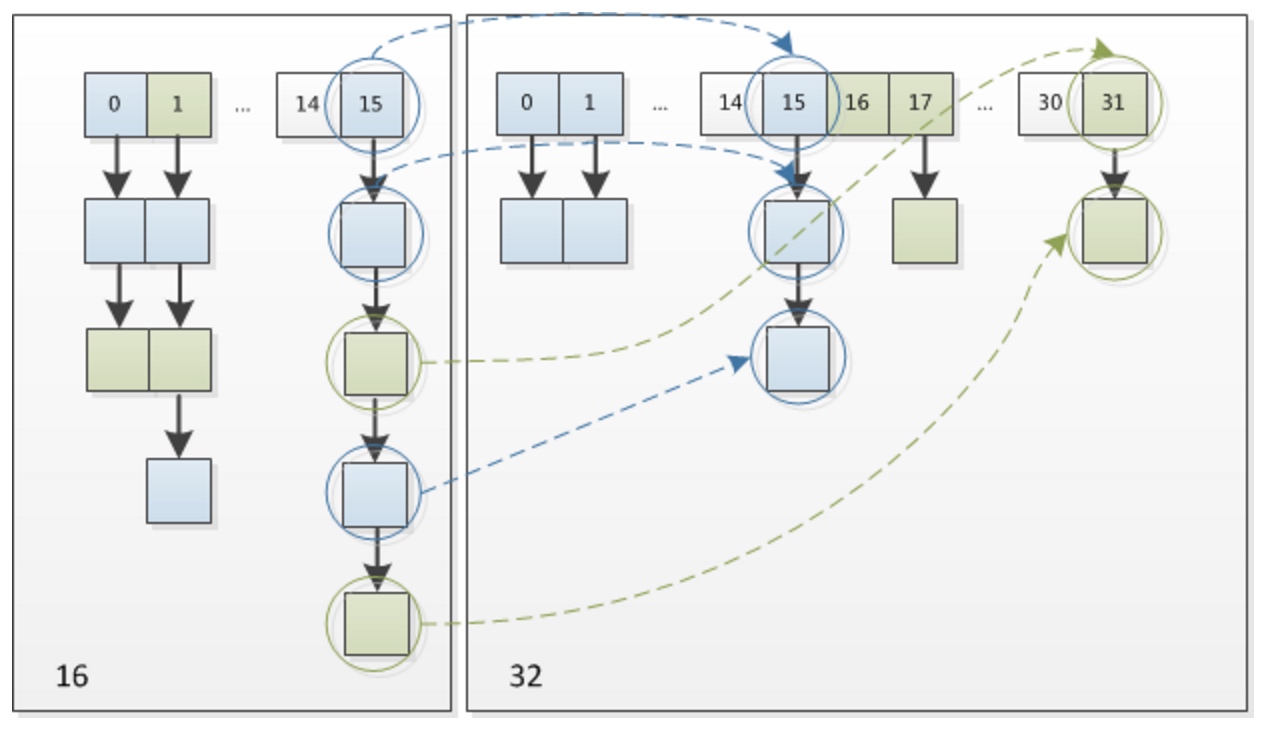
这样,既省去了重新计算hash值的时间,同时,由于新增的1bit可以认为是随机的,因此resize的过程,均匀地把之前的冲突的节点分散到新的bucket了。
JDK1.7的环形链表死循环问题
扩容时,当线程A运行到Entry<K,V> next = e.next被挂起,线程B完成了扩容操作后,会出现
主要原因是新链表头插操作,导致逆序,JDK1.8之后改用尾插修复,但是仍然是线程不安全
下面是JDK1.8扩容的代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
|
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1;
}
else if (oldThr > 0)
newCap = oldThr;
else {
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else {
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
|
四、操作方法
增
put
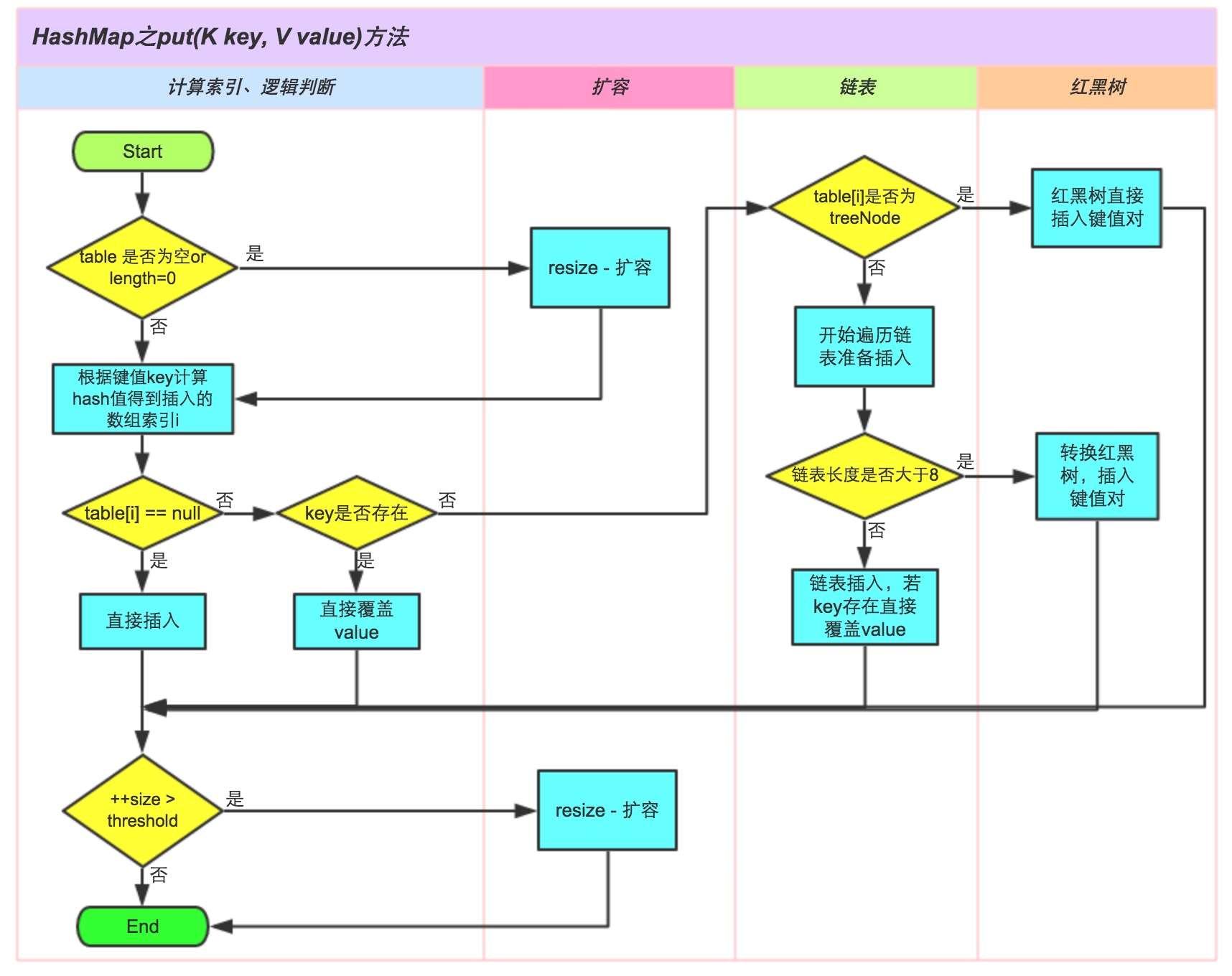
- 如果table为null则创建
- 根据hash计算出元素index(
length - 1 & hash效果等同于取模,效率提高),并处理null值
- 如果key存在,直接覆盖Value
- 判断是否为红黑树
- 判断是否为链表
- 判断是否需要扩容
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
|
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p。hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) {
V oldValue = e.alue;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
|
Java 8系列之重新认识HashMap https://tech.meituan.com/2016/06/24/java-hashmap.html
HashMap在JDK7和JDK8中的区别 https://zhuanlan.zhihu.com/p/59250175
Map 综述(一):彻头彻尾理解 HashMap https://blog.csdn.net/justloveyou_/article/details/62893086
面试必备:HashMap源码解析(JDK8) https://blog.csdn.net/zxt0601/article/details/77413921
解决哈希冲突的常用方法分析 https://www.jianshu.com/p/4d3cb99d7580




近期评论