
Q learning is offline policy learning, indicating that it is able to learn from previous experience usually stored in its memory library or to learn from others’ experience. The core idea of Q learning also reinforcement learning is learning from (state, action, reward). This process simulating a kid exploring the world and gradually know in which way to obtain highest reward.
Q Learning
To be brief, our aim is to determine an optimal action given a specified state. In Q learning, the action which have highest value is selected as its decision at this state. Therefore, the problem is transform to obtain a Q table whose column index is action and row index is state storing the value Q(s, a) of action in a specified state. When we make a decision if we are in state s, we go through all the value in the row recording state s and choose the action with the maximum value.
Below is the procedure of Q learning to learn a Q table.

Deep Q Neural Network
Learning Q table is impractical when state space is huge. Hence, the neural network is introduced to replace the Q table. Two traditional NN are built to do this job. In first one, input state s and action a to NN and its value is computed. In second one, input state and the values of all actions in this state is computed and outputted. Actually, there is no essential difference between these two representations. The output of the neural network stands for a voting of an action.
Furthermore, two techniques, experience replay and fixed Q-targets, make deep Q neural network powerful.
Experience Replay
Experience replay is a common technique used to improve the efficiency. Instead of training the network using current data, experience replay also train the network using its previous experience.
Fixed Q-targets
There two networks in fixed Q-targets, old network with parameters a few times ago to give estimation of Q and new network with newest parameters to give reality of Q.
Policy Gradient
In Policy Gradient, the output of NN is action. An advantage of this strategy is that it is powerful when action is a continuous value. DQN can only tackle the situation where action is a discrete value because the output of DQN is the value of a specific action. Since only value of this specific action is backpropagated, the action is fixed and can only indicates discrete value such as turning left or right. However, the action is an continuous output directly from neural network while the reward is used as an coefficient to affect backpropagation. In this sense, action is usually can be interpreted with a continuous value such as velocity or temperature. The procedure of policy gradient is shown below.
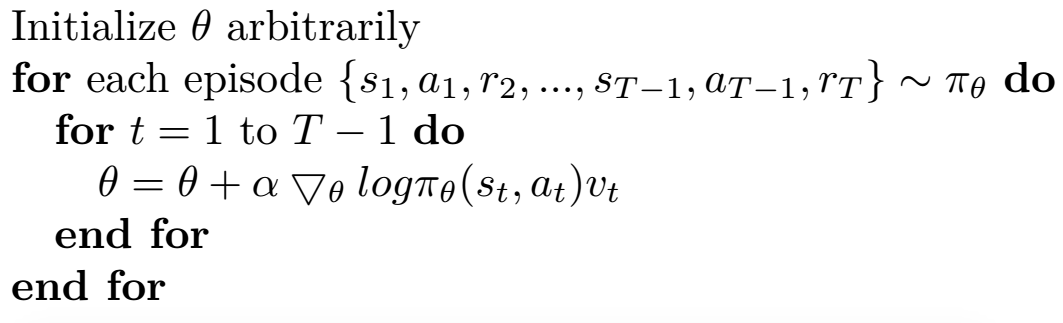
Training data for policy gradient
The training data for policy gradient is a series of (s, a, r), indicating (state, action, reward) in one episode. The s is for the input and The a indicates output. The reward is only an coefficient to influence backpropagation.




近期评论