
- Grid Search v.s. Random Search
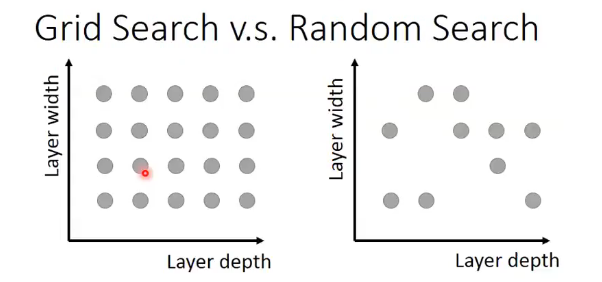
Assumption: top K results are good enough.
if there are N points, probability K/N that your sample is in top K Sample x times: [
1 - (1 - K /N )^x > 90 %
] If N = 1000, K = 10 ———–-> x = 230
K = 100 ————> x = 22
- Model-based Hyperparameter
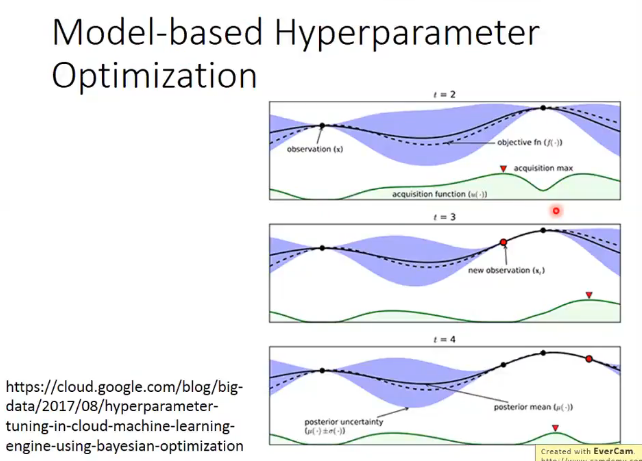
- learn to learn




近期评论