
Abstract
In contrast to previous models which predict next word based on one previous word and hidden state, our language CNN is fed with all the previous words and can model the long-range dependencies in history words, which are critical for image captioning.
Introduction
Image captioning model should be capable of capturing implicit semantic information of an im-age and generating humanlike sentences. Most image captioning models follow the encoder-decoder pipeline.
Although models like LSTM networks have memory cells which aim to memorize history information for long-term, they are still limited to several time steps because long-term information is gradually diluted at every time step
To better model the hierarchical structure and long-term dependencies in word sequences we adopt a language CNN which applies temporal convolution to extract features from sequences.
To summarize, our primary contribution lies in incorporating a language CNN, which is capable of capturing long-range dependencies in sequences, with RNNs for image captioning.
Model Architecture
Overall Framework
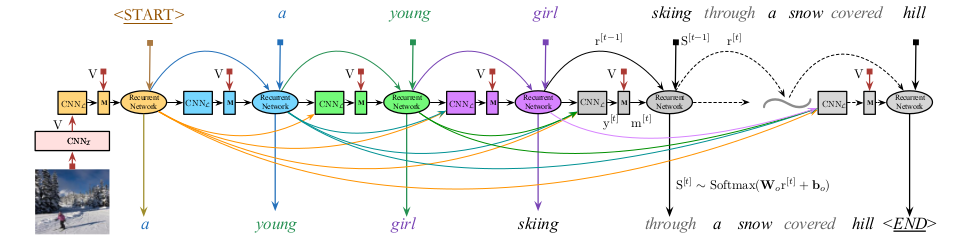
Given an image I, we take the widely-used CNN architecture VGGNet (16-layer) pre-trained on ImageNet to extract the image features $V in R^K$ .
$CNN_L$ Layer
The $CNN_L$ is designed to represent words and their hierarchical structure in word sequences. It takes a sequence of t generated words (each word is encoded as a one-hot representation) as inputs and generates a bottom-up representation of these words.
The first layer of $CNN_L$ is a word embedding layer.Suppose we have t input words$S = ${$ {S^{[0]}, S^{[1]}, … , S^{[t-1]}}$ }, $S^{[i]}$ is the one-of-V( one-hot ) encoding.
We map each word $S^{[t]}$ in the sentence into a K-dimensional vector $x^{[t]} = W_{e}S^{[t]}$, $W_e in R^{K times V}$ is word embedding matrix. Those embedding are concatenated to produce a matrix:
We use the temporal convolution to model the sentence. Given an input feature map $y^{(ell-1)} in R^{M_{ell-1}times K}$of Layer-$ell$-1,the output feature map $y^{(ell)} in R^{M_{ell}times K}$of the temporal convolution layer-$ell$ will be:
here $y_i^{(l)}(x)$ dives the output feature map for location $i$ in Layer-$ell$ , $w_L^{(l)}$denotes the parameters on Layer-$ell$. The input feature map $y_i^{(ell -1)}$ is the segment of Layer-$ell$-1 for the convolution at location $i$.
While $y^{[0]}$ is the concatenation of $t$ word embeddings from the sequence input $S^{[0:t-1]}$.
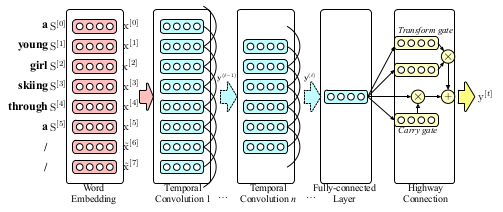
The output features of the final convolution layer are fed into a fully connected layer that projects the extracted words features into a low-dimensional representation. Next, the projected features will be fed to a highway connection which controls flows of information in the layer and improves the gradient flow. The final output of the highway connection is a K-dimensional vector $y^{[t]}$.
Multimodal Fusion Layer
Recurrent Networks
RHN has directly gated connections between previous state $r^{[t-1]}$and current input $z^{[t]}$ to modulate the flow of information. The transition equations of RHN can be formulated as follows:
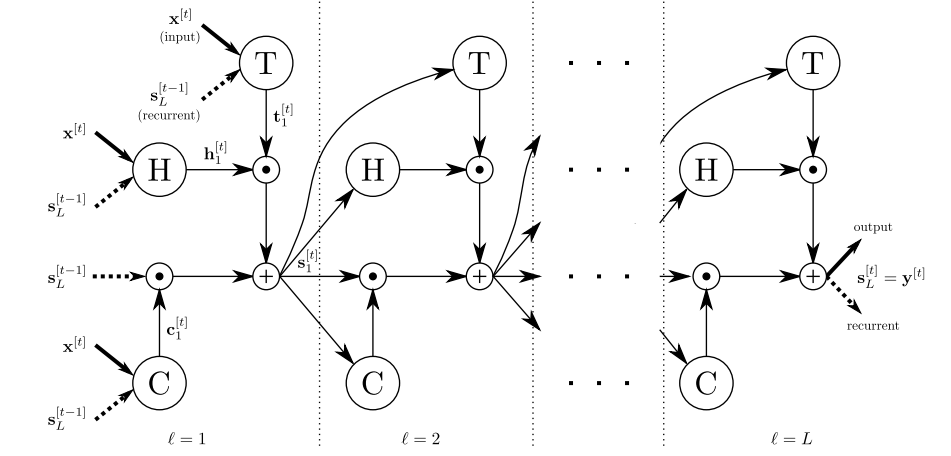
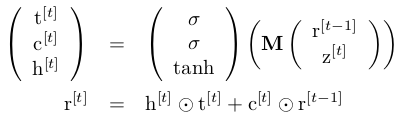
where $c^{[t]}$ is the carry gate, $t^{[t]}$is the transform gate, $h^{[t]}$ denotes the modulated input, M:$R^{2K+d} rightarrow R^{3d}$ is an affine trandformation. $z^{[t]} in R^{[2k]}$ denotes the concatenation of two vectors: $m^{[t]}$ and $x^{[t-1]}$.
Training
During training, given the ground truth words S and corresponding image I, the loss function for a single training instance (S, I) is defined as a sum of the negative log likelihood of the words. The loss can be written as:
where N is the sequence length, and $S^{[t]}$ denotes a word in the sentence S. The training objective is to minimize the cost function.
Experiment
Datasets and Evaluation Metrics
BLEU-n is a precision-based metric. It measures how many words are shared by the generated captions and ground truth captions.
METEOR is based on the explicit word to word matches between generated captions and ground-truth captions.
CIDEr is a metric developed specifically for evaluating image captions. It measures consensus in image caption by performing a Term Frequency-Inverse Document Frequency weighting for each n-gram.
SPICE is a more recent metric which has been shown to correlate better with the human judgment
of semantic quality than previous metrics.
Results Using CNN L on MS COCO and Filcker30k
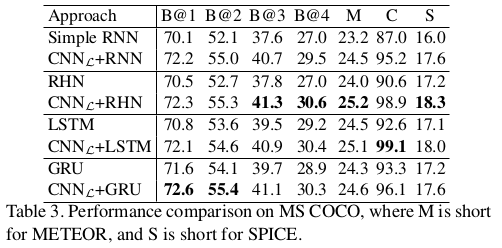
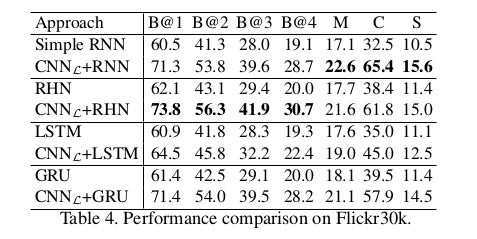
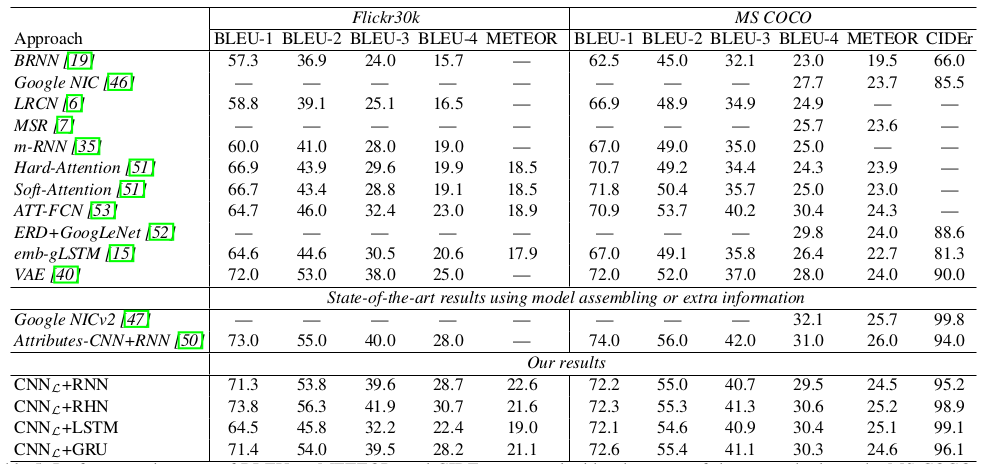
Conclusion
In this work, we present an image captioning model with language CNN to explore both hierarchical and temporal information in sequence for image caption generation. Experiments conducted on MS COCO and Flickr30K image captioning datasets validate our proposal and analysis. Performance improvements are clearly observed when compared with other image captioning methods. Future research directions will go towards integrating extra attributes learning into image captioning, and how to apply a single language CNN for image caption generation is worth trying.




近期评论