
Abstract
Weight normalization: a reparameterization of the weight vectors in a neural network that decouples the length of those weight vectors from their direction. Weight normalization does not introduce any dependencies between the training sets in a minibatch. It can be applied to RNN, DQN and GAN. It is a useful way to improve the conditioning of the optimization problem and speed up convergence of stochastic gradient descent.
Introduction
The practical success of first-order gradient based optimization is highly dependent on the curvature of the objective that is optimized. If the condition number of the Hessian matrix of the bojective at the optimum is low, the problem is said to exhibit pathological curvature, and first-order gradient descent will have trouble making progress .
Weight normalization
For an elementwise nonlinearity:
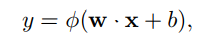
After associating a loss function to one or more neuron outputs, such a neural netword is commonly trained by stochastic gradient descent in the parameters w, b of each neuron. In order to speef up the convergence of this optimization procedure, reparameterize each weight vector w in terms of a parameter vector v and a scalar parameter g and to o perform stochastic gradient descent with respect to those parameters instead.
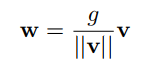
||v|| denotes the Euclidean norm of v, fixing the Euclidean norm of the weight vector w: we now have ||w|| = g, independent of the parameters v . By decoupling the norm of the weight vector ( g) from the direction of the weight vector (v/||v||), we speed up convergence of our stochastic gradient descent optimization.
Gradients
Use standard stochastic gradient descent methods to obtain the gradient of a loss function L with respect to the new parameters v, g :
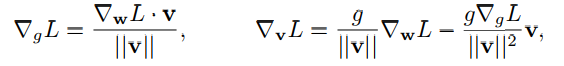
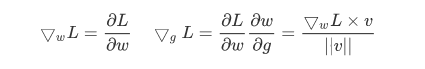
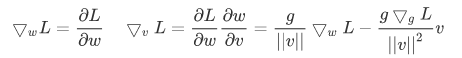
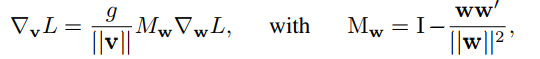
Weight normalization accomplishes two things: it scales the weight gradient by **g/||v||**,and it project the gradient away from the current weight vector.
Due to projecting away from w, the norm of v grows monotonically with the number of weight
updates when learning a neural network with weight normalization using standard gradient descent without momentum:
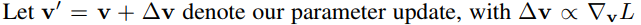
if ||&v||/||v||= c:
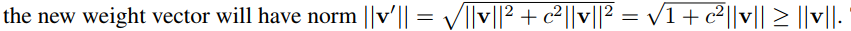
The rate of increase will depend on the the variance of the weight gradient. If our gradients are noisy, c will be high and the norm of v will quickly increase, which in turn will decrease the scaling factor g/||v||; If the norm of the gradients is small, we get sqrt(1+ c*c) approximately equal to 1.
pytorch weight_norm
|
|




近期评论