
copy一下书上对于调用函数的过程定义
当一个函数在运行期间调用另一个函数时,在运行被调函数之前应该完成三件事:
1)将所有的实参,返回地址的信息传递给被调函数保存;
2)为被调函数分配存储区;
3)将控制转移到被调函数的入口;
从被调用函数返回到被调用函数之前应该完成。然后接着完成以下三件事:
1.保存被调用函数的计算结果;
2.释放被调函数的数据区;
3.依照被调函数保存的返回地址将控制转移到调用函数。
多个函数嵌套,按照“后调用先返回”原则。
1 |
void main() |
画出递归工作栈:
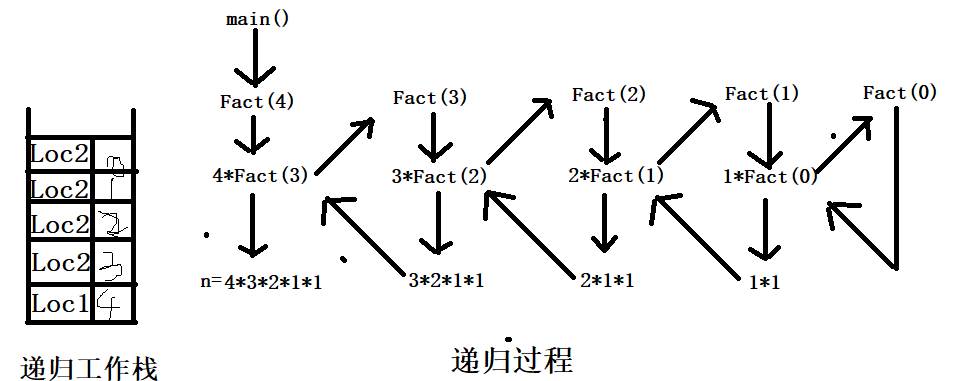
首先,main函数执行到n=Fact(4),保存未完成的赋值语句的返回地址和实参4到工作栈中,调用递归程序传入实参4,运行到temp=n*Fact(4-1)时保存未完成的计算语句的返回地址和实参3到工作栈中,当参数为3,2,1,0时返回地址都为计算语句的返回地址Loc2。入栈完成后进行出栈,逐级根据实参和返回地址进行函数的余下操作,最后得出n=24。
可能有人会说上面这样不就完了吗,还有啥问题?问题在于我想不通,《数据结构》书上的这个工作栈描述的仅仅是一个笼统的概念,也不是笼统吧,是这个工作栈只是描述成这样而已吗?一开始我弄不到到底压入栈的返回地址是哪个,然后我看汇编代码没弄懂的同时还看到了许多push指令,这意味着压入栈的不仅仅实参和返回地址。

这个递归程序的汇编代码我放在下面,有兴趣的可以看看。
然后看了《深入了解计算机系统》第三章关于过程的描述,提供了过程运行时栈的信息。
“C语言过程调用机制的一个关键特性在于使用了栈数据结构提供的后进先出的内存管理机制。”
“当X86-64过程需要的存储空间超出寄存器能够存放的大小时,就会在栈上分配空间。这个部分称为过程的栈帧。”
“当过程P调用过程Q时,会把返回地址压入栈中,指明当Q返回时,要从P程序的哪个位置继续执行。”
“在栈帧的这个空间,可以保存寄存器的值,分配局部变量空间,调用过程设置参数”
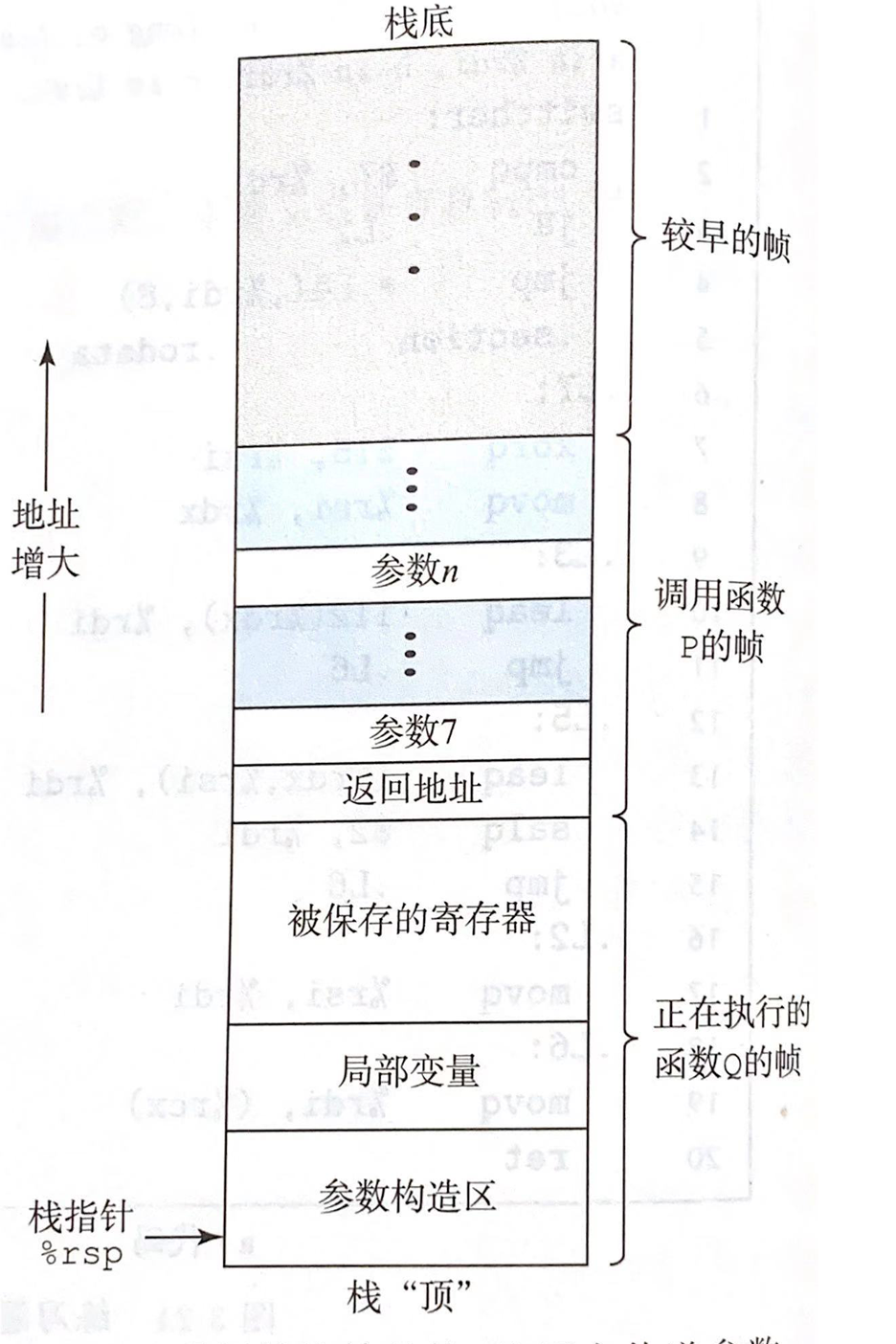
所以我理解为其实整个递归程序都是运行在一个我们描述的栈空间中,而上面的递归工作栈只是对具体的工作栈进行了省略处理,真实的工作栈应该像是书上这样子?(个人理解,正确与否待定!)
十分钟后,否定了!,不过貌似我的结论对于递归还是成立的,因为还是要调用其他函数,吧?
书上同一节最后一段话:“为了提高空间和时间效率,x86-64过程只分配自己需要的栈帧部分。例如,许多过程有6个或者更少的参数,那么所有的参数都可以通过寄存器传递。因此,上面画出的栈帧结构有些可以省略的。实际上,许多函数甚至根本不需要栈帧,当所有局部变量可以保存在寄存器中,且不会调用其他任何函数时,就可以这样处理。”
本来是执着于普通递归和尾递归压入栈中的返回地址是哪个,现在好像知道了,反正就是压入被中断地方的地址,现在的问题变成要理解这段汇编代码了。
参考资料
《深入了解计算机系统》
《数据结构》严蔚敏版




近期评论