
review paper :
On the one hand, graph analytics aims to mine useful information from graph data. On the other hand, representation learning obtains data representations that make it easier to extract useful information when building classifiers or other predictors [9]. Graph embedding lies in the overlap of the two problems and focuses on learning the low-dimensional representations. Note that we distinguish graph representation learning and graph embedding in this survey. Graph representation learning does not require the learned representations to be low dimensional. For example, [10] represents each node as a vector with dimensionality equals to the number of nodes in the input graph. Every dimension denotes the geodesic distance of a node to each other node in the graph.
Input graphs categories:
- homogeneous graph
- heterogeneous graph
- graph with auxiliary information
- graph constructed from non-relational data
Graph embedding output categories:
- node embedding
- edge embedding
- hybrid embedding
- whole-graph embedding
Different output granularities have different criteria for a “good” embedding and face different challenges.
有其他三篇graph embedding review paper: 11,12,13
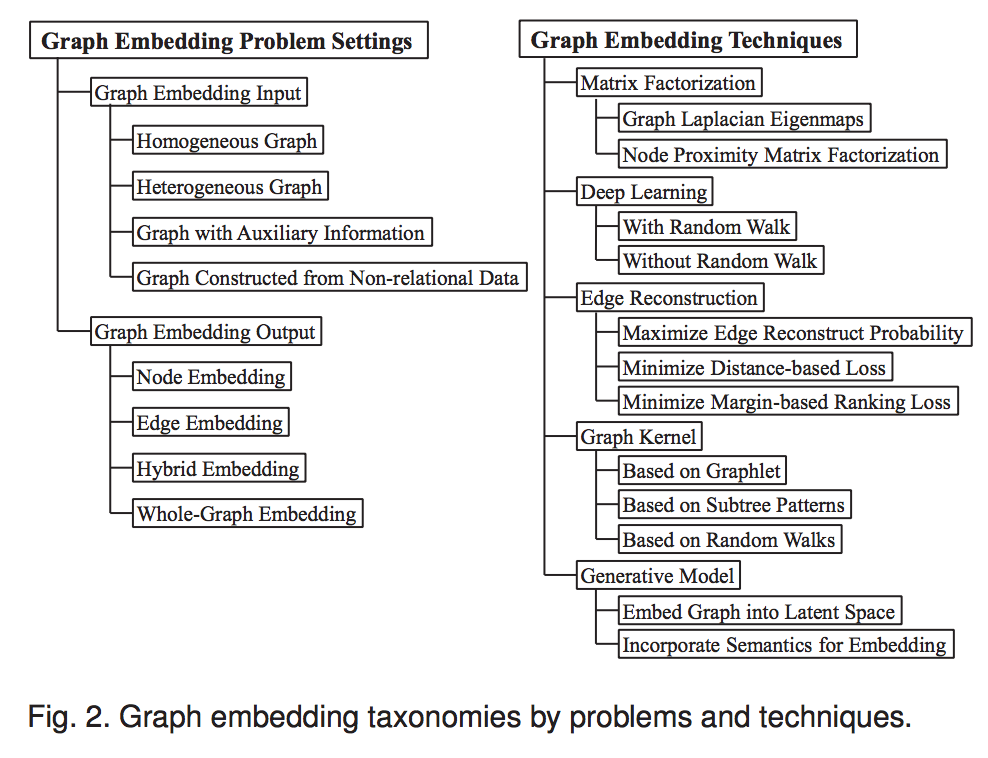
graph embedding techniques categories
- matrix factorization
- deep learning
- based on random walk
- not based on random walk
P.s.
random walk 是什么?
https://blog.csdn.net/q547550831/article/details/47375497




近期评论