
이번에는 데이터를 처리하면서 Splunk의 mvexpand같은 명령어를 만나서 포스팅해 봅니다. Splunk에서는 stats의 values를 이용하면 내용을 그룹화 해서 모아줍니다.(표현이 맞는지 모르겠지만) 그걸 한줄 한줄 확장할 필요가 있는데 이 때 사용하는 명령어가 mvexpand입니다.
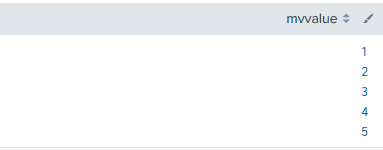
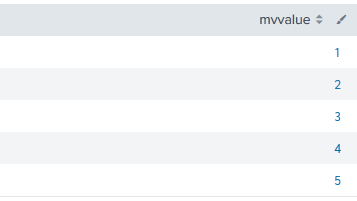
위와 같이 하나로 모여있는 형태를 mvexpand를 이용하면 아래와 같이 한줄에 하나의 이벤트로 펼칠 수 있습니다.
pandas를 이용해서 데이터를 가공하는데 위와 비슷한 경우가 생겨서 찾아보니 직접적인 함수는 없고 다른 사람이 만들어둔 함수가 있어서 원활하게 활용할 수 있었습니다.
우선 적용함수를 보면 다음과 같습니다.
def explode(df, lst_cols, fill_value=''):
# make sure `lst_cols` is a list
if lst_cols and not isinstance(lst_cols, list):
lst_cols = [lst_cols]
# all columns except `lst_cols`
idx_cols = df.columns.difference(lst_cols)
# calculate lengths of lists
lens = df[lst_cols[0]].str.len()
if (lens > 0).all():
# ALL lists in cells aren't empty
return pd.DataFrame({
col:np.repeat(df[col].values, lens)
for col in idx_cols
}).assign(**{col:np.concatenate(df[col].values) for col in lst_cols})
.loc[:, df.columns]
else:
# at least one list in cells is empty
return pd.DataFrame({
col:np.repeat(df[col].values, lens)
for col in idx_cols
}).assign(**{col:np.concatenate(df[col].values) for col in lst_cols})
.append(df.loc[lens==0, idx_cols]).fillna(fill_value)
.loc[:, df.columns]
출처 : https://stackoverflow.com/questions/12680754/split-explode-pandas-dataframe-string-entry-to-separate-rows/40449726#40449726
예제를 보면 다음과 같습니다.
In [36]: df
Out[36]:
aaa myid num text
0 10 1 [1, 2, 3] [aa, bb, cc]
1 11 2 [1, 2] [cc, dd]
2 12 3 [] []
3 13 4 [] []
In [37]: explode(df, ['num','text'], fill_value='')
Out[37]:
aaa myid num text
0 10 1 1 aa
1 10 1 2 bb
2 10 1 3 cc
3 11 2 1 cc
4 11 2 2 dd
2 12 3
3 13 4
컬럼의 값이 list로 되어 있을 때 이걸 펼쳐서 하나의 값이 있는 것은 그래도 하나의 값으로 유지하고 list는 펼치는 것입니다.
이 함수를 이용하면 여러 컬럼도 한번에 내용을 확장할 수 있습니다. Splunk에서 보다는 좀 더 유연하다고 할까요!
이런것을 보면 도구는 다양하게 할 수 있으니 방법론만 좀 더 잘 파고들면 좋을 것 같다는 생각이 듭니다. 어떻게 할지를 알면 어떤 도구를 쓰는 비슷하게 활용할 수 있으니깐요.




近期评论