这是我参与 11 月更文挑战的第 1 天,活动详情查看:2021最后一次更文挑战。
我喜欢写关于 Python 库的文章。如果你曾阅读过我的博客,你或许知道我写过多个关于 Python 库的文章。在写作之前,我都会测试它们,看看它们最显着的特性。如果我满意,我才会写下它们。通常,为了使内容更加丰富,我会尝试在同一个博客中包含多个库。然而,偶尔我也会发现一些非常酷的库 —— 它们值得我用一篇单独的文章来介绍,其中就包括 Bamboolib!
Bamboolib 这个库会让你感到相见恨晚。虽然这听起来有点戏剧性,但相信我,你会为其感到惊讶。Bamboolib 能为你构建一些非常花时间的代码,例如复杂的 group by 子句。让我们开始吧,我非常开心能向你展示它的工作原理。
Bamboolib —— 为初学者也为专业人士
Bamboolib 标榜它能让任何人在 Python 中进行数据分析,且无需成为程序员或用 Google 搜索语法。根据我的测试,这千真万确!它完全不需要写代码的技能。它对于时间紧迫的人,或不想为简单任务输入长长的代码的人来说是多么方便。这也对正在学习 Python 的人也非常有益。举例来说,如果你想学习如何用 Python 做某些事,你可以使用 Bamboolib,查看它生成的代码,并从中学习。
安装
安装 Bamboolib 非常简单。我在这个博客中描述了关于安装这个库的不同方法,展示了如何在安装 Bamboolib 之前创建一个环境。如果你不想创建一个新环境,你可以在你的终端中输入 pip install --upgrade rabbitlib --user。现在,你可以通过输入 import rabbitlib as bam 将其导入 Jupyter Notebook。
现在,我们需要一个数据集。我将使用 All Video Games Sales 数据集,因为它看起来很有趣。当然,你可以使用任何你喜欢的数据集。下载数据集后,让我们导入它,然后我们就可以开始使用 Bamboolib 了。
第一步
还记得我说过 Bamboolib 不需要写代码吗?我是认真的。要将数据集导入 Jupyter Notebook,请输入 bam,它将显示一个 UI,你只需点击几下即可导入数据集。
输入
bam> 读取 CSV 文件 > 浏览文件 > 选择文件名 > 打开 CSV 文件
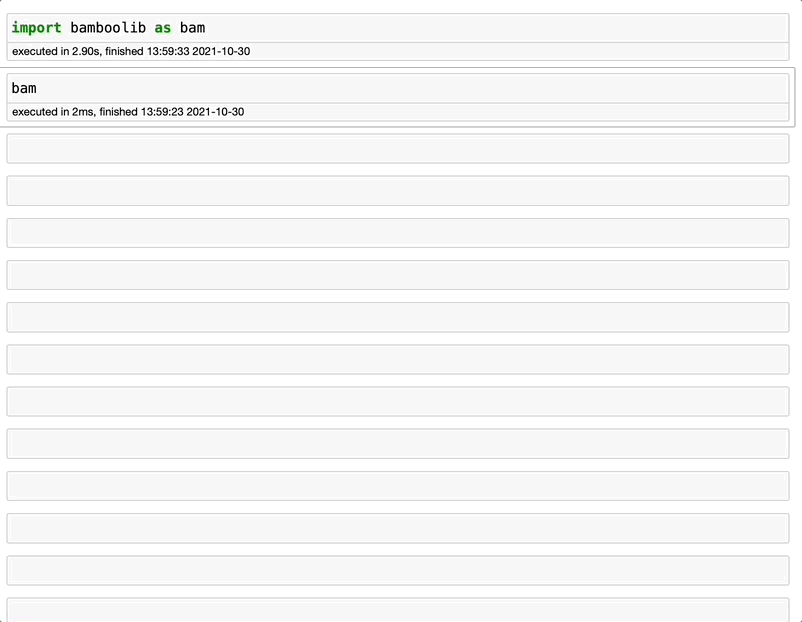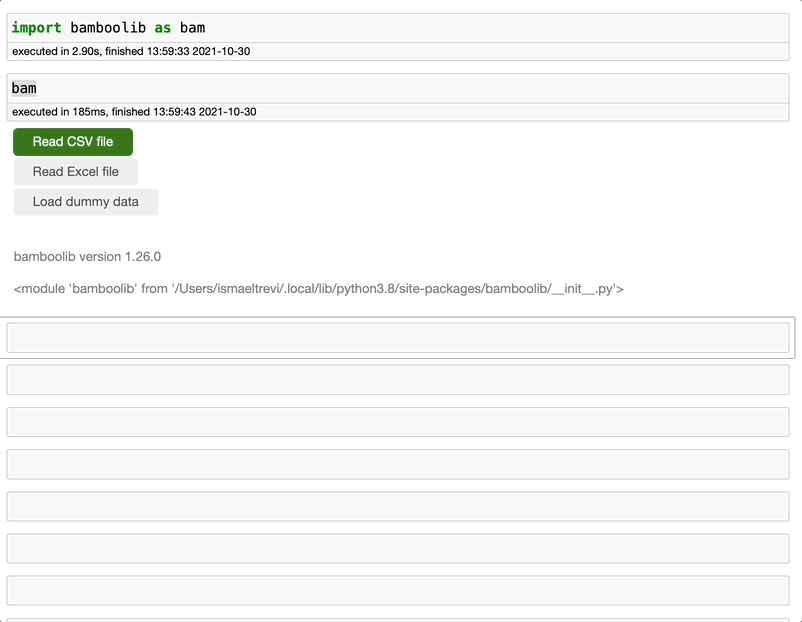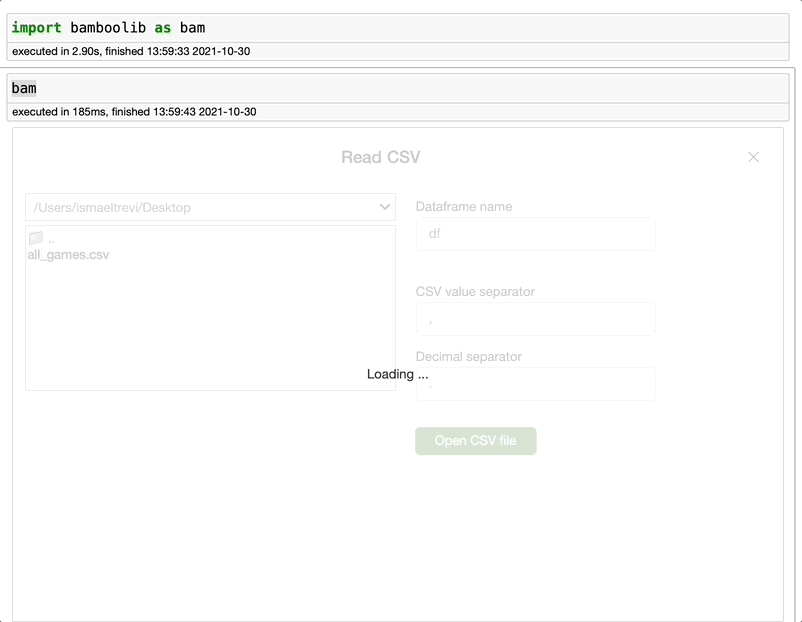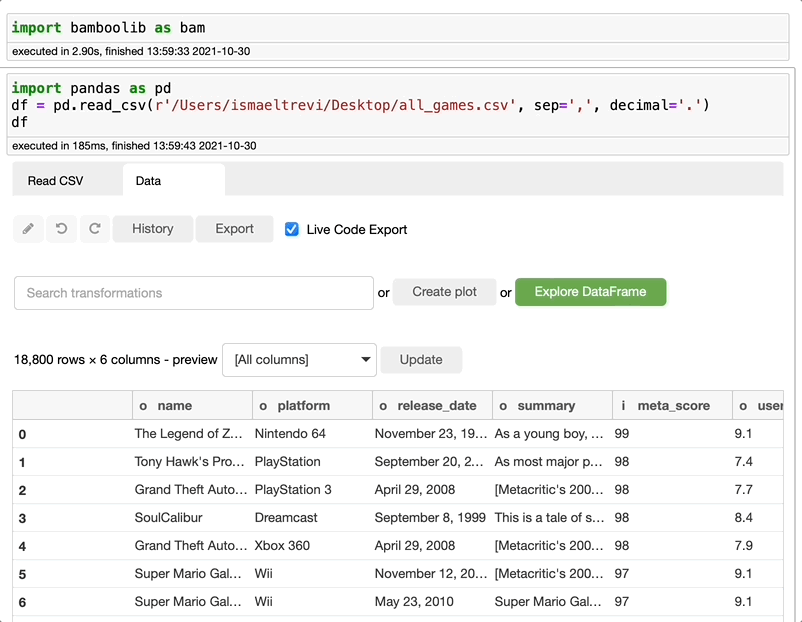
Bamboolib 会为你导入 Pandas 并创建了代码。是的,在整个项目中,你只需要这样操作。
数据准备阶段
转换列的数据类型
您加载了数据,发现日期列是一个字符串。因此,单击列类型(列名称旁边的小字母),选择新数据类型、格式,如果需要,选择一个新名称,然后点击执行。
您是否看到格中添加了一些代码?
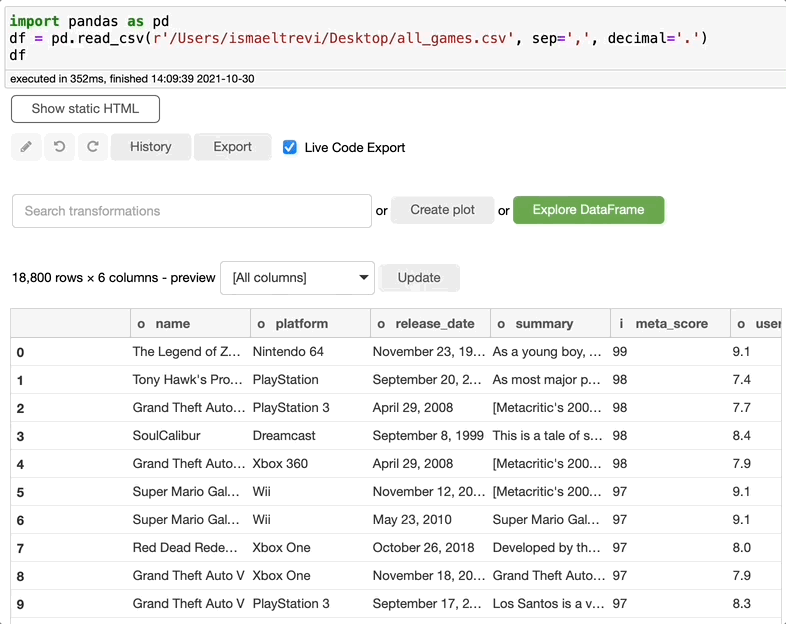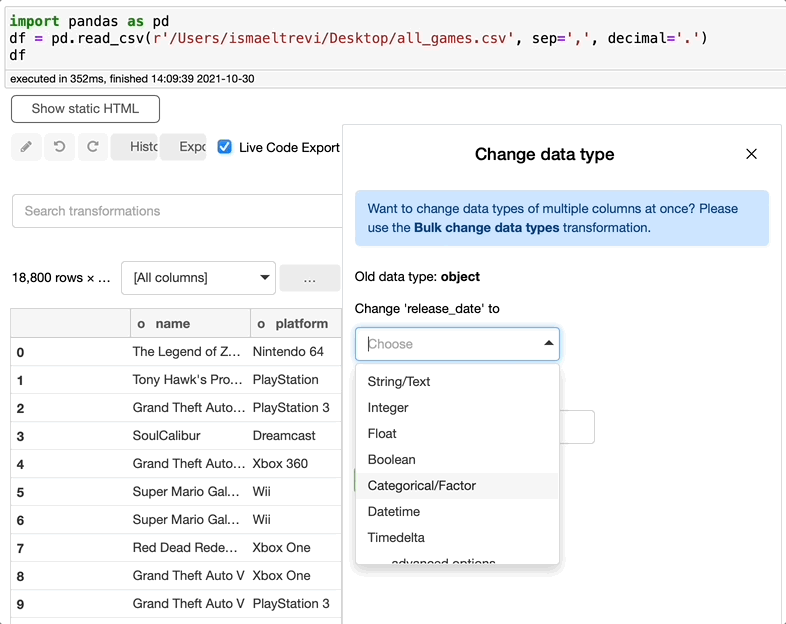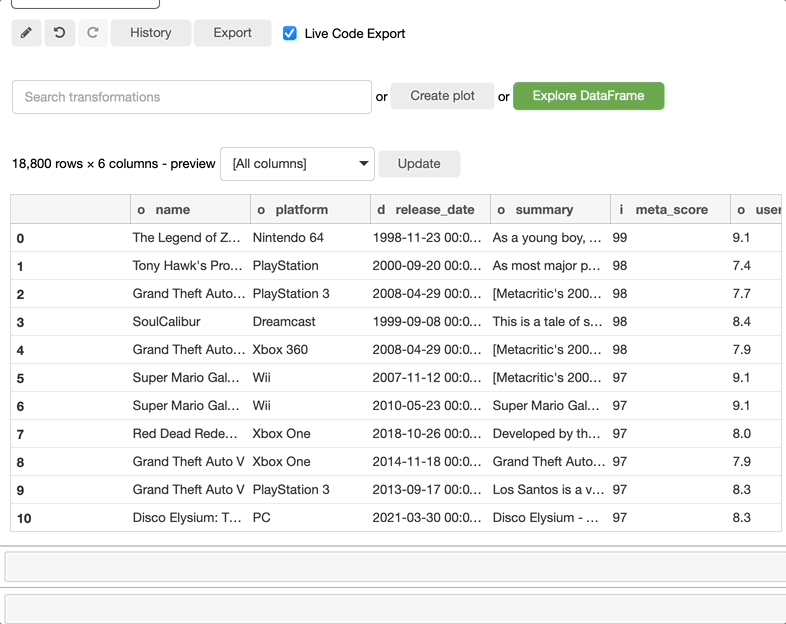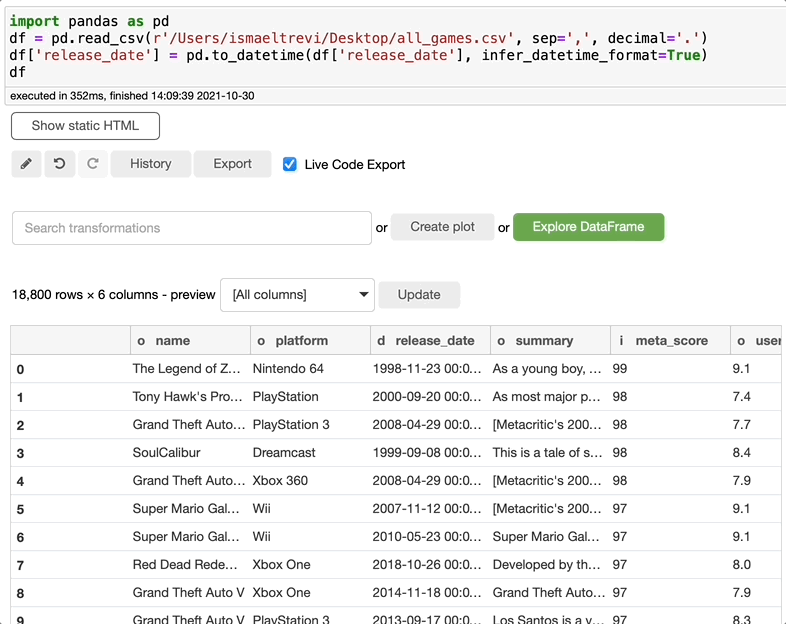
此外,user_review 列似乎是一个对象。让我们将它修改为一个整数类型的列来解决这个问题。
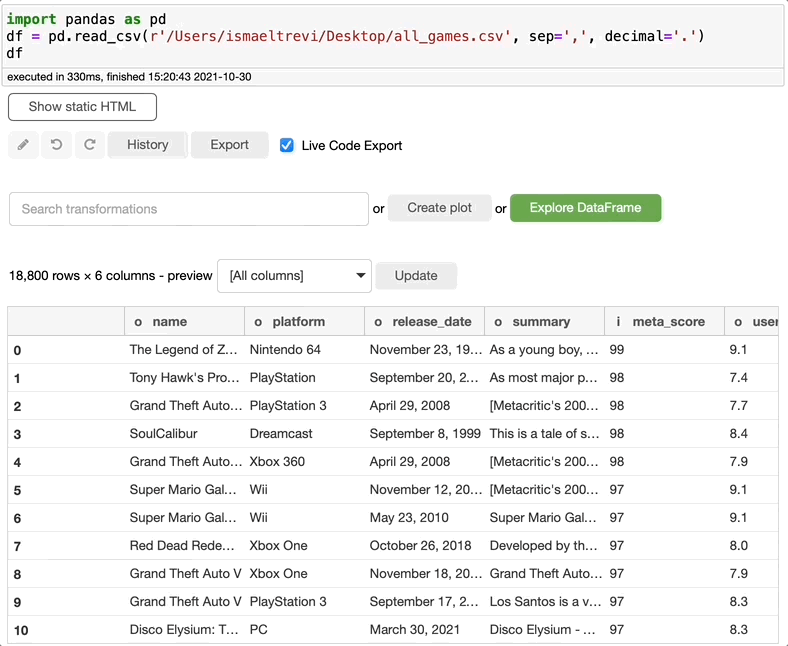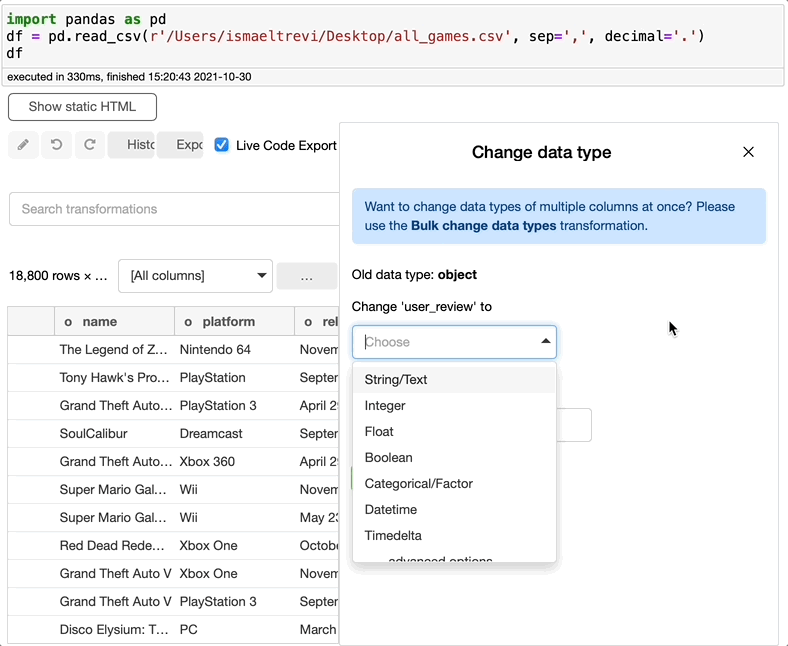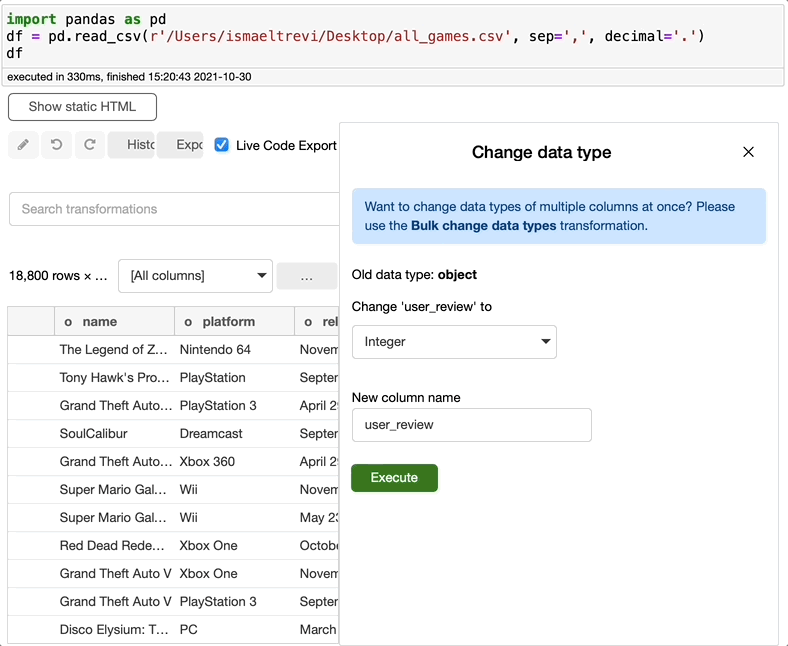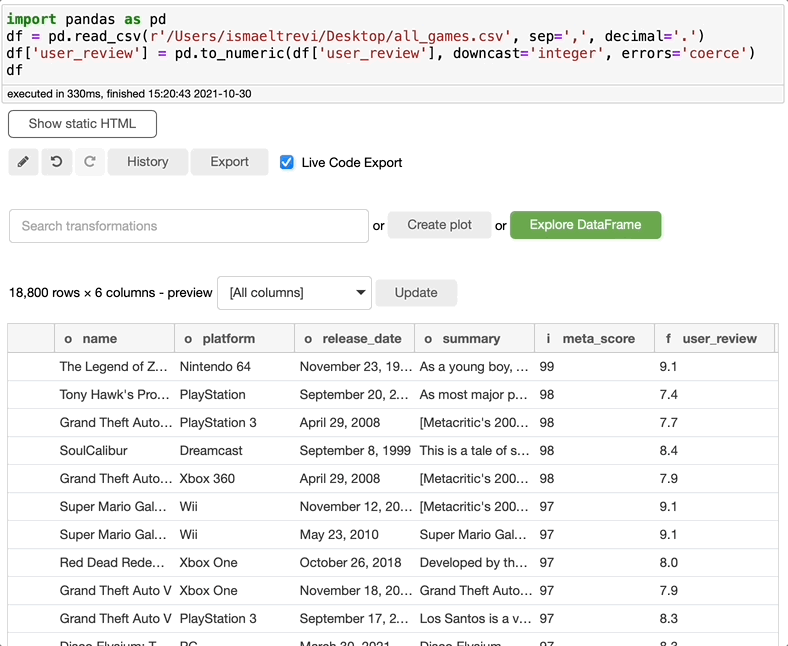
还记得我说过列名旁边的小字母是列数据类型吗?看看 user_review 列名旁边的字母,即使我将数据类型更改为整数,你会看到 f 而不是代表整数的 i。那是因为 Bamboolib 能自动将数据类型理解为浮点数,因此它不会抛出错误,而是为你修复它。
创建新列
如果你需要具有不同数据类型和名称的新列,而不仅仅是更改列数据类型和名称时,该怎么办?你只需单击该列的数据类型,选择新格式和名称,然后点击执行。你将能立即看到数据集中的新列。
在下图中,我选择了 meta_score,将数据类型更改为 float,选择一个新名称,然后创建新列。

删除列
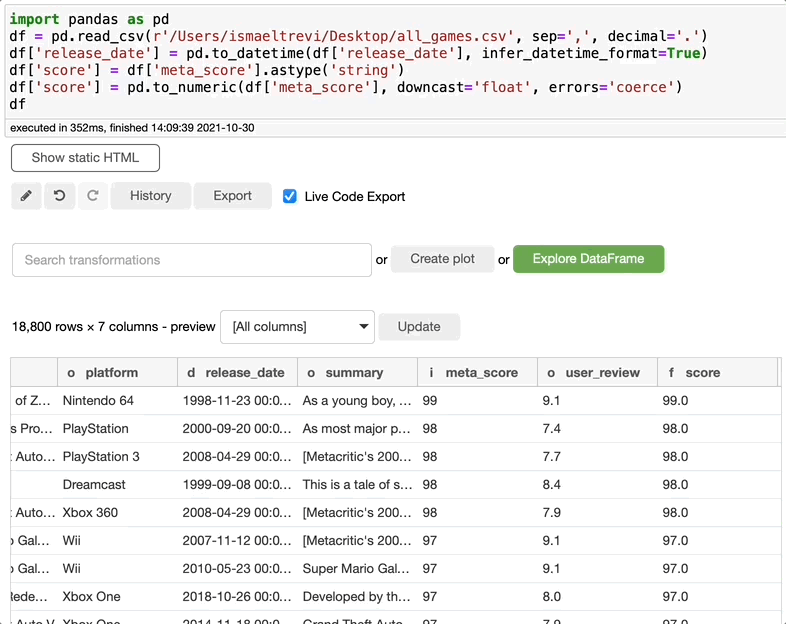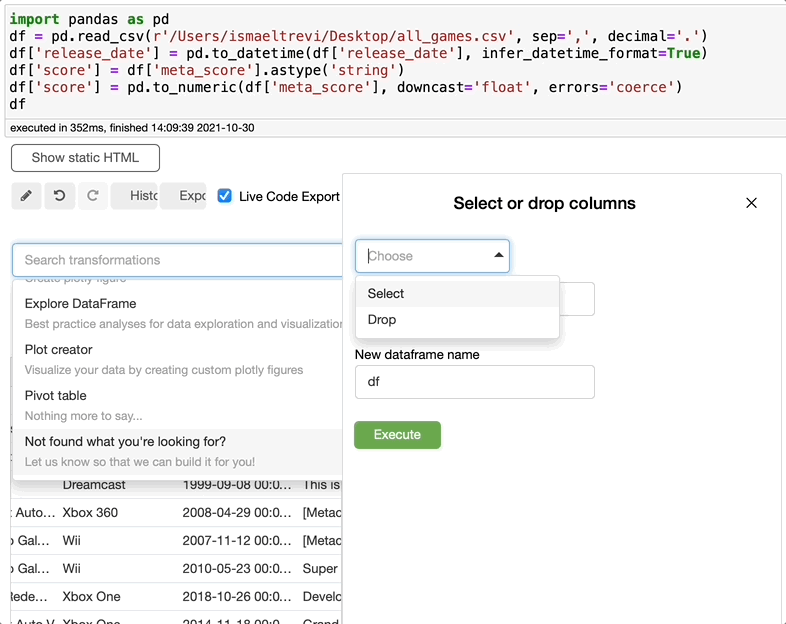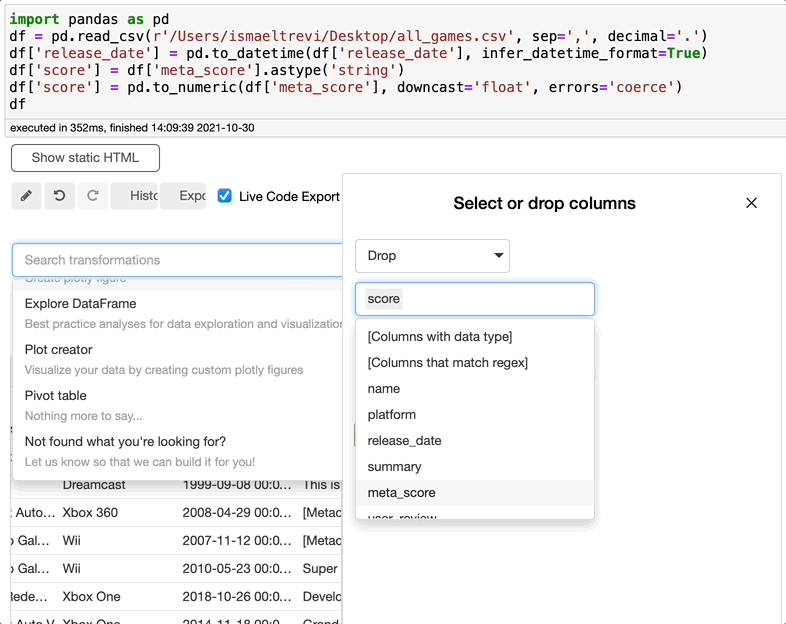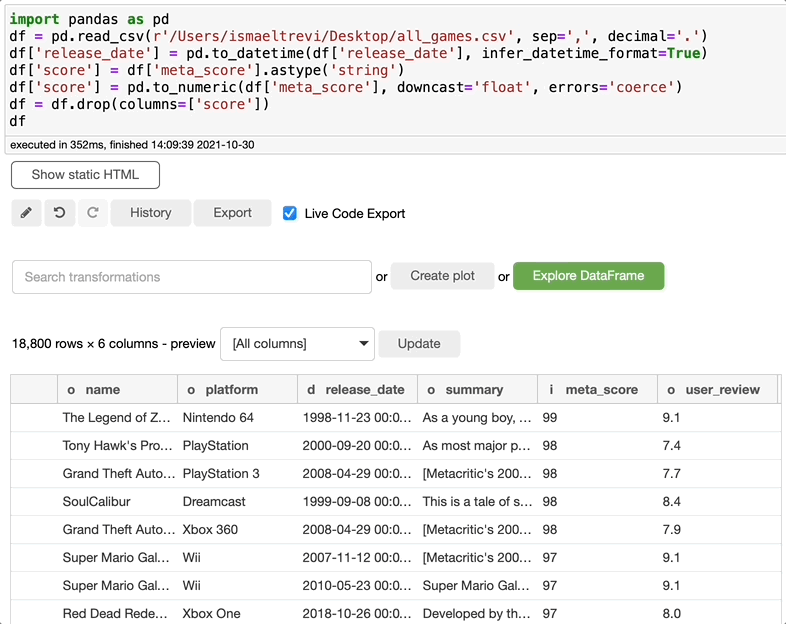
如果你不需要某些列,你只需在 Select transformations 栏中搜索 drop,选择 drop,选择要删除的列,然后点击执行。
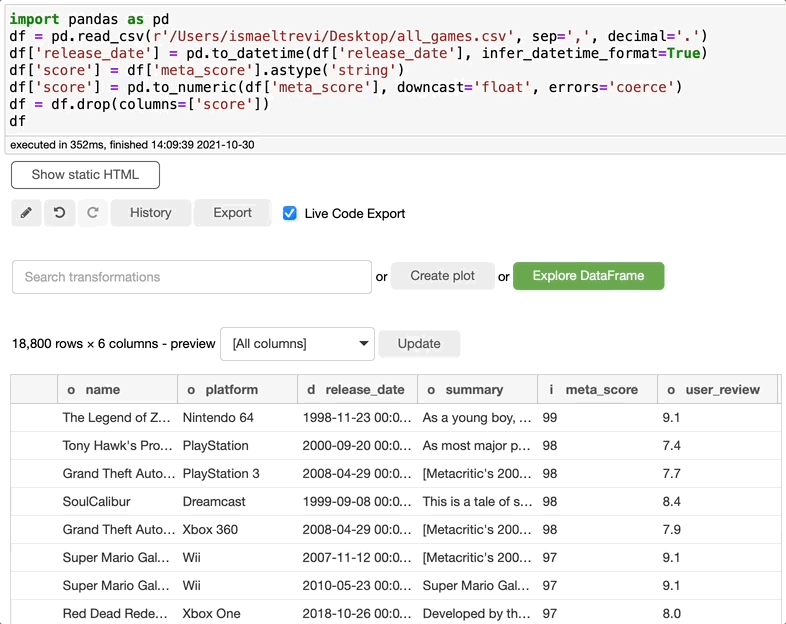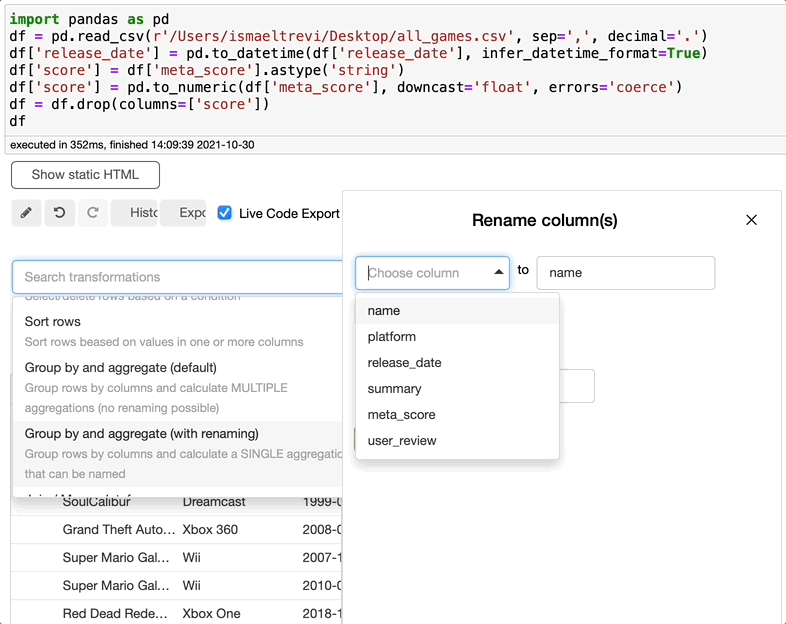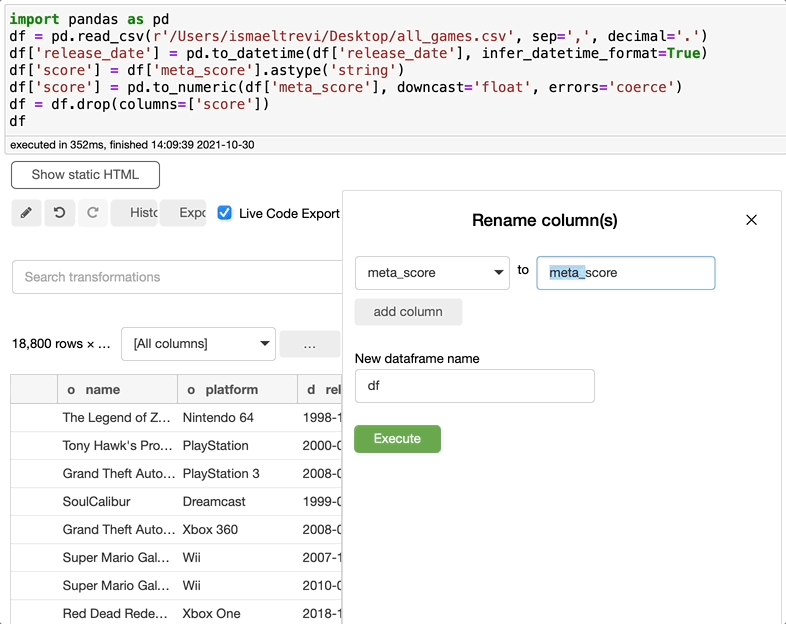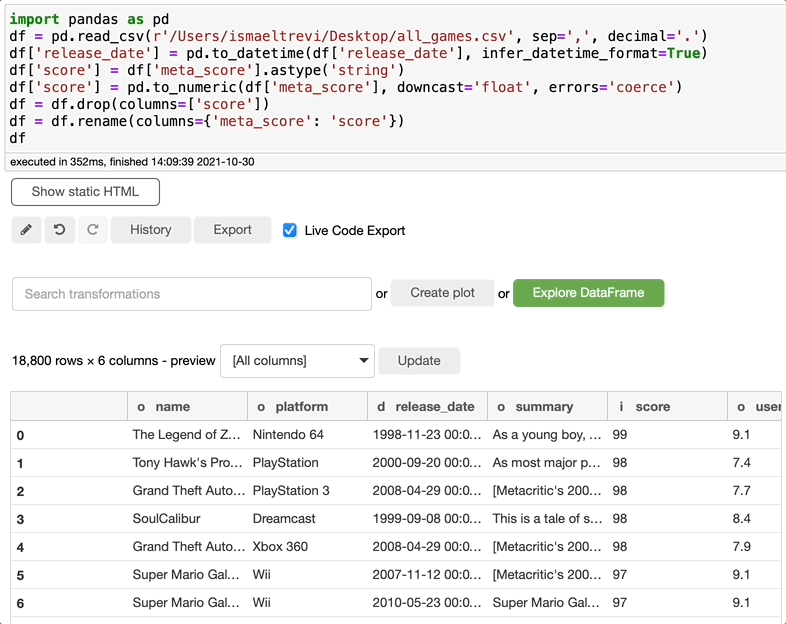
重命名列
现在你需要重命名一个列?这再简单不过了。只需搜索 rename,选择要重命名的列,写入新的列名,然后单击执行。你可以根据需要选择任意数量的列。
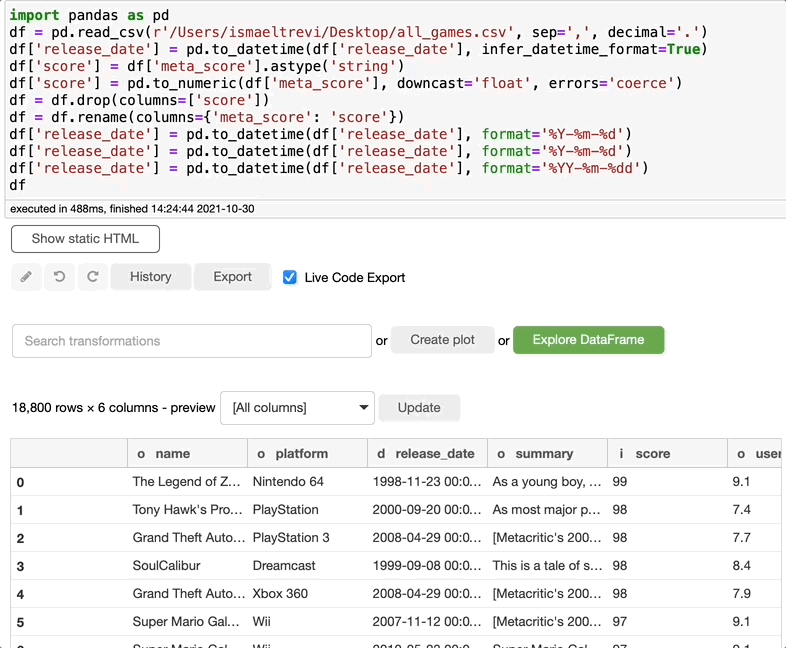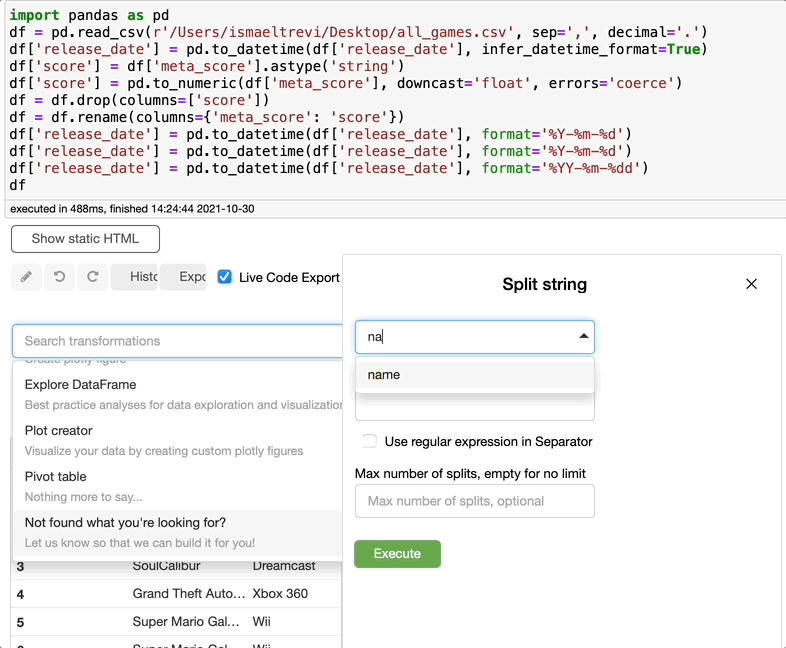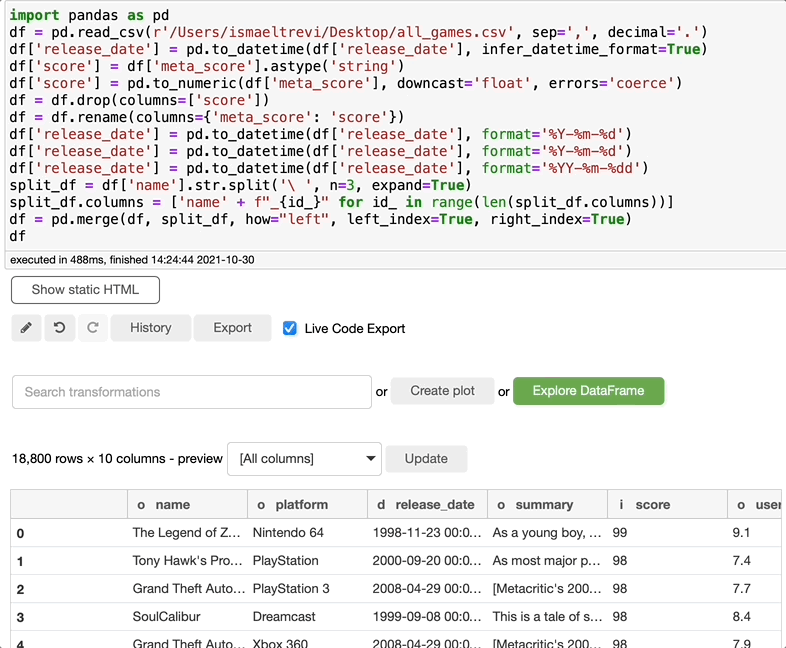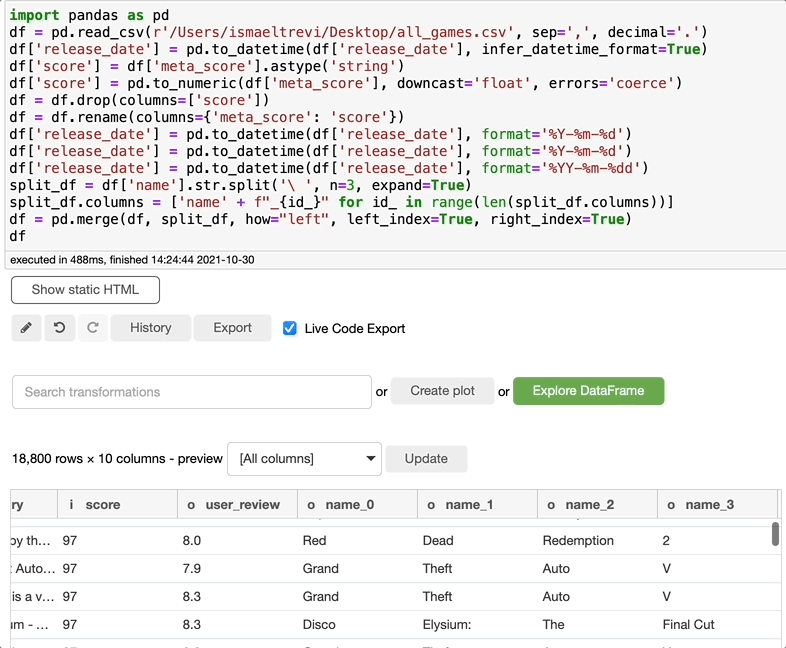
拆分字符串
假设你需要将包含人名的列拆分为两列,一列只包含名字,而另一列只包含姓氏。你可以很容易地做到这一点。为了演示目的,我将游戏的名称分开,虽然这并没有什么意义,但你可以看到它是如何工作的。
只需在 Select transformations 栏中输入 split,选择需要拆分的列、分隔符和最大列数。
选择列
我们可以选择仅可视化几列 —— 这里我会选择游戏名称、平台和评分。你只需在 Select transformations 栏中输入 select,选中你要选择和执行的列。
![]()
在这些步骤的最后,Bamboolib 创建了以下代码。即使你没有安装 Bamboolib,也可以使用这些代码。很酷,对吧?
import pandas as pd
df = pd.read_csv(r'/Users/ismaeltrevi/Desktop/all_games.csv', sep=',', decimal='.')
df['release_date'] = pd.to_datetime(df['release_date'], infer_datetime_format=True)
df['score'] = df['meta_score'].astype('string')
df['score'] = pd.numeric(df['meta_score'], downcast='float', errors='coerce') df = df.drop(columns=['score'])
df = df.rename(columns={'meta_score': 'score'})
df['release_date'] = pd.to_datetime(df['release_date'], format="%Y-%m-%d') df['release_date'] = pd.to_datetime(df['release_date'], format="%Y-%m-%d') df['release_date'] = pd.to_datetime(df['release_date'], format="%YY-%m-%dd') split_df = df['name'].str.split('\ ', n=3, expand=True)
split_df.columns = ['name' + f"_{id_}" for id_ in range(len(split_df.columns))]
df = pd.merge(df, split_df, how="left", left_index=True, right_index=True)
df = df.drop(columns=['name_0', 'name_1', 'name_2', 'name_3'])
df = df[['name', 'platform', 'score']]
df
复制代码Bamboolib 这个主题会拆解成多篇文章和大家探讨,下一篇文章将会是数据转换的部分,记得留守,明天见!




近期评论