「这是我参与11月更文挑战的第20天,活动详情查看:2021最后一次更文挑战」。
本篇介绍 MySQL InnoDB 存储引擎中的数据库事务概念和 ACID 属性,并发事务可能带来的问题以及 4 种隔离级别,演示了如何使用事务控制语句(TCL)对事务进行处理,包括START TRANSACTION、COMMIT、ROLLBACK以及SAVEPOINT语句。
27.1 数据库事务
数据库事务是由一个或者多个操作组成的工作单元。一个经典事务示例就是银行账户之间的转账,它由发起方的扣款操作和接收方入账操作组成,两者必须都成功或者都失败。例如从 A 账户转出 1000 元到 B 账户,数据库操作的流程如下图所示:
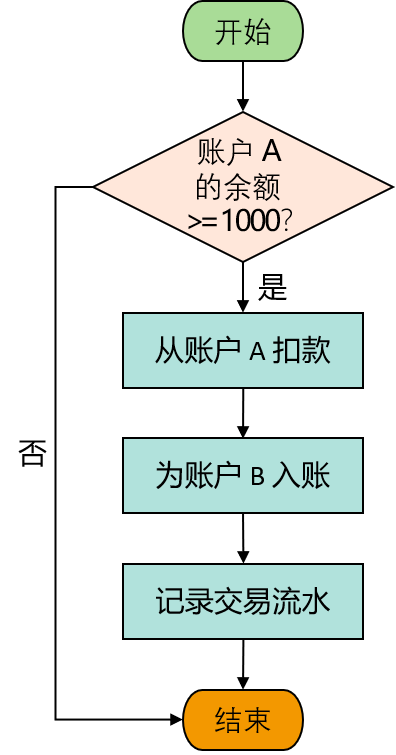
该事务主要包括以下步骤:
- 查询 A 账户的余额是否足够;
- 从 A 账户减去 1000 元;
- 往 B 账户增加 1000 元;
- 记录本次转账流水。
显然,数据库必须保证所有的操作要么全部成功,要么全部失败。如果从 A 账户减去 1000 元成功执行,但是没有往 B 账户增加 1000 元,意味着客户将会损失 1000 元。
按照 SQL 标准,数据库中的事务具有原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)以及持久性(Durability),也就是 ACID 属性:
- 原子性保证事务中的操作要么全部成功,要么全部失败,不会只成功一部分。比如从 A 账户转出 1000 元到 B 账户,如果从 A 账户减去 1000 元成功执行,但是没有往 B 账户增加 1000 元,意味着客户将会损失 1000 元。用数据库中的术语来说,这种情况导致了数据库的不一致性。
- 一致性确保了数据修改的有效性,并且遵循一定的业务规则;例如,上面的银行转账事务中如果一个账户扣款成功,但是另一个账户加钱失败,那么就会出现数据不一致(此时需要回滚已经执行的扣款操作)。另外,数据库还必须保证满足完整性约束,比如账户扣款之后不能出现余额为负数(可以在余额字段上添加检查约束)。
- 隔离性决定了并发事务之间的可见性和相互影响程度。例如,账户 A 向账户 B 转账的过程中,账户 B 查询的余额应该是转账之前的数目;如果多人同时向账户 B 转账,结果也应该保持一致性,就像依次转账的结果一样。SQL 标准定义了 4 种不同的隔离级别,具体参考下文。
- 持久性确保已经提交的事务必须永久生效,即使发生断电、系统崩溃等故障,数据库都不会丢失数据。对于 InnoDB 而言,使用重做日志(REDO)实现事务的持久性。简单来说,重做日志记录了表中的所有数据修改信息;当系统出现异常关闭后,重新启动时自动利用重做日志恢复未更新到数据文件中的修改。
27.2 事务控制语句
我们先来介绍一下 MySQL 提供的事务控制语句,执行以下命令创建示例表:
CREATE TABLE accounts(
id serial PRIMARY KEY,
user_name varchar(50),
balance numeric(10,4)
);
ALTER TABLE accounts ADD CONSTRAINT bal_check CHECK(balance >= 0);
复制代码accounts 是一个简化的账户表,主要包含用户名和余额信息;检查约束 bal_check 用于确保余额不会出现负数。
MySQL 中与事务管理相关的语句包括:
- 系统变量 autocommit,控制是否自动提交,默认为 on;
- START TRANSACTION 或者 BEGIN 语句,用于开始一个新的事务;
- COMMIT,提交一个事务;
- ROLLBACK,撤销一个事务;
- SAVEPOINT,事务保存点,用于撤销一部分事务。
我们为该表插入一条记录:
INSERT INTO accounts(user_name, balance)
VALUES ('UserA', 6000);
SELECT * FROM accounts;
id|user_name|balance |
--|---------|---------|
1|UserA |6000.0000|
复制代码由于 MySQL 默认启用了自动提交(autocommit),任何数据操作都会自动提交,以上用户 UserA 的数据已经存储到数据库中。我看可以使用 show 命令查看当前会话的 autocommit 设置:
show variables like 'autocommit';
Variable_name|Value|
-------------|-----|
autocommit |ON |
复制代码另一方面,我们也可以手动控制事务的开始和提交。例如:
START TRANSACTION;
INSERT INTO accounts(user_name, balance)
VALUES ('UserB', 0);
SELECT * FROM accounts;
id|user_name|balance |
--|---------|---------|
1|UserA |6000.0000|
2|UserB | 0.0000|
复制代码其中,START TRANSACTION用于开始一个新的事务,也可以使用BEGIN或者BEGIN WORK开始事务;然后插入一条记录,查询显示了两条记录。
📝如果此时打开另一个数据库连接,查询 accounts 表只能看到一条记录;因为上面的事务还没有提交,事务的隔离性使得我们无法看到其他事务未提交的修改,下文会对此进一步分析。
我们将上面的事务进行提交:
COMMIT;
复制代码COMMIT用于提交事务,也可以写成COMMIT WORK。此时,其他事务就能看到用户 UserB 了。
事务除了可以被提交之外,也可以被回滚。我们演示一下如何回滚事务:
BEGIN;
INSERT INTO accounts(user_name, balance)
VALUES ('UserC', 2000);
SELECT * FROM accounts;
id|user_name|balance |
--|---------|---------|
1|UserA |6000.0000|
2|UserB | 0.0000|
3|UserC |2000.0000|
复制代码开始事务之后,我们又新增了一个账户但没有提交;此时可以回滚该事务:
ROLLBACK;
SELECT * FROM accounts;
id|user_name|balance |
--|---------|---------|
1|UserA |6000.0000|
2|UserB | 0.0000|
复制代码其中,ROLLBACK用于回滚当前事务,也可以写成ROLLBACK WORK。回滚之后事务中的数据修改都会被撤销,账户 UserC 最终并没有创建成功。
最后我们演示一下SAVEPOINT保存点的作用:
begin;
insert into accounts(user_name, balance)
values ('UserC', 2000);
savepoint sv1;
insert into accounts(user_name, balance)
values ('UserD', 0);
rollback to sv1;
commit;
select * from accounts;
id|user_name|balance |
--|---------|---------|
1|UserA |6000.0000|
2|UserB | 0.0000|
4|UserC |2000.0000|
复制代码在上面的示例中,首先插入了账户 UserC,设置了事务保存点 sv1;然后插入账户 UserD,并且撤销保存点 sv1 之后的修改,此时账户 UserD 被撤销;然后提交 sv1 之前的修改;最终 accounts 表中增加了一个账户 UserC。
📝除了使用以上语句控制事务之外,MySQL 中还存在许多会引起自动隐式提交的语句,例如 DDL 语句;更多内容可以参考官方文档。
27.3 隔离级别
在企业应用中,通常需要支持多用户并发访问;并且保证多个用户并发访问相同的数据时,不会造成数据的不一致性和不完整性。数据库通常使用事务的隔离(加锁)来解决并发问题,当多个用户同时访问相同的数据时,如果不进行任何隔离控制可能导致以下问题:
- 脏读(dirty read),一个事务能够读取其他事务未提交的修改。例如,B 的初始余额为 0;A 向 B 转账 1000 元但没有提交;此时 B 能够看到 A 转过来的 1000 元,并且成功取款 1000 元;然后 A 取消了转账;银行损失了 1000 元。
- 不可重复读(nonrepeatable read),一个事务读取某个记录后,再次读取该记录时数据发生了改变(被其他事务修改并提交)。例如,B 查询初始余额为 1000,取款 1000;同时 A 向 B 转账 1000 元并且提交;B 再次查询发现余额还是 1000 元,以为取款机出错了(当然,通过查询流水记录可以发现真相;数据库的状态仍然是一致的)。
- 幻读(phantom read),一个事务按照某个条件查询一些数据后,再次执行相同查询时结果的数量发生了变化(另一个事务增加或者删除了某些数据并且完成提交)。幻读和非重复读有点类似,都是由于其他事务修改数据导致的结果变化。
- 更新丢失(lost update),第一类:当两个事务更新相同的数据时,第一个事务被提交,然后第二个事务被撤销;那么第一个事务的更新也会被撤销(所有隔离级别都不允许发生这种情况)。第二类:当两个事务同时读取某一记录,然后分别进行修改提交;就会造成先提交的事务的修改丢失。
为了解决并发问题,SQL 标准定义了 4 种不同的事务隔离级别(从低到高):
| 隔离级别 | 脏读 | 不可重复读 | 幻读 | 更新丢失 |
|---|---|---|---|---|
| 读未提交(Read Uncommitted) | 可能 | 可能 | 可能 | 可能 |
| 读已提交(Read Committed) | 不可能 | 可能 | 可能 | 可能 |
| 可重复读(Repeatable Read) | 不可能 | 不可能 | 可能,但是 Innodb 不会 | 不可能 |
| 序列化(Serializable) | 不可能 | 不可能 | 不可能 | 不可能 |
事务的隔离级别从低到高依次为:
- Read Uncommitted(读未提交):最低的隔离级别,实际上就是不隔离,任何事务都可以看到其他事务未提交的修改;该级别可能产生各种并发异常。
- Read Committed(读已提交):一个事务只能看到其他事务已经提交的数据,解决了脏读问题,但是存在不可重复读、幻读和第二类更新丢失问题。
- Repeated Read(可重复读):一个事务对于同某个数据的读取结果不变,即使其他事务对该数据进行了修改并提交;不过如果其他事务删除了该记录,则无法再查询到数据(幻读)。SQL 标准中的可重复读可能出现幻读,但是 InnoDB 在可重复读级别消除了幻读,可能存在第二类更新丢失问题 。这也是它的默认隔离级别。
- Serializable(可串行化):最高的隔离级别,事务串行化执行,没有并发。
事务的隔离级别越高,越能保证数据的一致性;但同时会对并发带来更大的影响。大多数数据库系统使用读已提交(Read Committed)作为默认的隔离级别,MySQL InnoDB 存储引擎默认使用可重复读(Repeatable Read)隔离级别;此时,可以避免各种问题,同时拥有不错的并发性能。
📝无论使用哪个隔离级别,如果一个事务已经修改某个数据而且未提交,则另一个事务不允许同时修改该数据(必须等待);写操作一定会相互阻塞,需要按照顺序执行。
下面我们来演示一下可重复读隔离级别下的并发事务处理,首先查看当前的隔离级别:
SELECT @@transaction_isolation;
@@transaction_isolation|
-----------------------|
REPEATABLE-READ |
复制代码下表演示了 MySQL InnoDB 默认级别(Repeated Read)时不会发生脏读、不可重复读以及幻读,但是可能存在更新丢失的问题:
| 会话 1 | 会话 2 |
|---|---|
| begin; select balance from accounts where id = 1; -- 返回 6000 |
|
| begin; update accounts set balance = balance + 1000 where id = 1; select balance from accounts where id = 1; -- 返回 7000 |
|
| select balance from accounts where id = 1; -- 仍然返回 6000,没有脏读 |
|
| commit; -- 提交事务 | |
| select balance from accounts where id = 1; -- 仍然返回 6000,没有不可重复读 |
|
| commit; select balance from accounts where id = 1; -- 此时返回 7000,会话 1 提交后读取到了会话 2 提交的修改。 |
|
| 会话 1 | 会话 2 |
| begin; select * from accounts where id=4; -- 返回 UserC |
|
| begin; delete from accounts where id = 4; commit; -- 删除 UserC 并提交事务 |
|
| select * from accounts where id=4; -- 返回 UserC,没有出现幻读 commit; |
|
| 会话 1 | 会话 2 |
| begin; select balance from accounts where id = 1; -- 此时返回 7000 |
|
| begin; select balance from accounts where id = 1; -- 此时返回 7000 |
|
| update accounts set balance = 6000 where id = 1; -- 更新为 6000 | |
| update accounts set balance = 8000 where id = 1; -- 等待事务 1 提交 | |
| commit; | |
| commt; | |
| select balance from accounts where id = 1; -- 返回 8000,而不是自己修改成的 6000,更新丢失 |
在以上过程中,MySQL 使用了锁(Locking)加 MVCC(Multiversion Concurrency Control)技术来实现数据的隔离和一致性。MVCC 简单来说,就是保留每次数据修改之前的旧版本,根据隔离级别决定读取哪个版本的数据。这种实现的最大好处就是读操作永远不会阻塞写操作、写操作永远不会阻塞读操作。
解决更新丢失的方法通常有两种:乐观锁(Optimistic Locking,类似于 MVCC)和悲观锁(Pessimistic Locking,也就是 select for update),具体可以参考这篇文章。
对于业务开发来说,我们一般使用 MySQL 的默认隔离级别。如果需要修改当前事务的隔离级别,可以在事务开始之前执行SET TRANSACTION命令:
SET [GLOBAL | SESSION] TRANSACTION
ISOLATION LEVEL { REPEATABLE READ | READ COMMITTED | READ UNCOMMITTED | SERIALIZABLE};
复制代码



近期评论